3.3.1
Binning de características numéricas
<p>El <b>binning</b> (discretización) convierte un rasgo continuo en categorías ordenadas. Es útil cuando un modelo no acepta valores reales o cuando queremos crear variables como "徠uintil de ingreso"・</p>
Ancho fijo vs. frecuencia igual #
Sea (x_1, \dots, x_n) un rasgo numérico. Una regla de binning divide el rango en intervalos (I_k) y sustituye cada (x_i) por la etiqueta del intervalo donde cae.
- Bins de ancho fijo (
pandas.cut) utilizan intervalos de igual longitud. - Bins de frecuencia igual (
pandas.qcut) dividen los datos ordenados para que cada intervalo contenga aproximadamente el mismo número de observaciones.
Los bins de frecuencia igual son más estables ante colas largas, mientras que los de ancho fijo conservan información sobre la distancia.
Visualizando bins de cuantiles #
| |
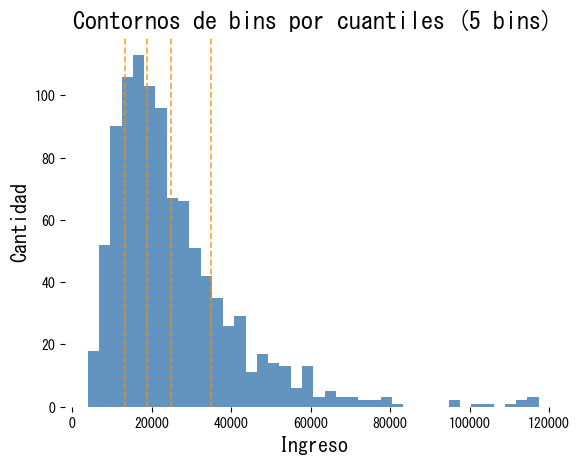
Comparando qcut y cut
#
| |
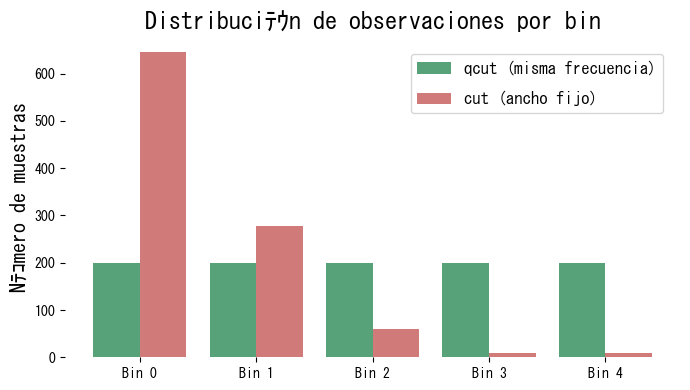
Con qcut cada bin recibe prácticamente el mismo número de observaciones. En cambio, con cut los datos se concentran en las zonas densas, dejando a los extremos con muy pocos registros.
Consejos #
- Recorta outliers extremos antes de aplicar bins de ancho fijo; un solo valor puede expandir el rango y dejar bins vacíos.
- Guarda los puntos de corte generados durante el entrenamiento y reutilízalos en producción para mantener definiciones consistentes.
- En modelos basados en árboles el binning suele ser innecesario, pero en modelos lineales permite capturar efectos no lineales sin agregar demasiadas variables.