まとめ- Accuracy は全予測のうち正しく分類できた割合を示す指標です。
- 乳がん診断データで Accuracy と Balanced Accuracy を比較し、不均衡データの落とし穴を検証します。
- Accuracy だけで判断せず補助指標を併用する際の注意点を整理します。
1. 定義
#
混同行列の各要素(真陽性 TP / 偽陽性 FP / 偽陰性 FN / 真陰性 TN)を用いると Accuracy は次式で表せます。
$$
\mathrm{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN}
$$正解件数の割合を一目で確認できますが、クラス不均衡がある場合は補助指標と併せて評価する必要があります。
2. Python 3.13 での実装と可視化
#
まずは Python のバージョンを確認し、必要なライブラリをインストールします。
1
2
| python --version # 例: Python 3.13.0
pip install scikit-learn matplotlib
|
乳がん診断データセットにランダムフォレストを適用し、Accuracy と Balanced Accuracy を比較する棒グラフを描画します。Pipeline と StandardScaler を活用し、再利用しやすい形にまとめています。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| from __future__ import annotations
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, balanced_accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.preprocessing import StandardScaler
def build_model(random_state: int = 42) -> Pipeline:
"""乳がん診断データを分類するランダムフォレストのパイプラインを構築する。"""
return make_pipeline(
StandardScaler(),
RandomForestClassifier(random_state=random_state, n_estimators=300),
)
def plot_accuracy_comparison() -> None:
"""Accuracy と Balanced Accuracy を比較する棒グラフを生成・保存する。"""
features, labels = load_breast_cancer(return_X_y=True)
x_train, x_test, y_train, y_test = train_test_split(
features,
labels,
test_size=0.25,
stratify=labels,
random_state=42,
)
pipeline = build_model()
pipeline.fit(x_train, y_train)
predictions = pipeline.predict(x_test)
acc = accuracy_score(y_test, predictions)
bal_acc = balanced_accuracy_score(y_test, predictions)
print(f"Accuracy: {acc:.3f}, Balanced Accuracy: {bal_acc:.3f}")
figure, axis = plt.subplots(figsize=(5, 4))
scores = np.array([acc, bal_acc])
labels = ["Accuracy", "Balanced Accuracy"]
colors = ["#2563eb", "#f97316"]
axis.bar(labels, scores, color=colors)
axis.set_ylim(0, 1.05)
axis.set_ylabel("Score")
axis.set_title("Accuracy vs. Balanced Accuracy (Breast Cancer Dataset)")
axis.grid(axis="y", linestyle="--", alpha=0.4)
for label, score in zip(labels, scores, strict=True):
axis.text(label, score + 0.02, f"{score:.3f}", ha="center", va="bottom")
figure.tight_layout()
output_dir = Path("static/images/eval/classification/accuracy")
output_dir.mkdir(parents=True, exist_ok=True)
figure.savefig(output_dir / "accuracy_vs_balanced.png", dpi=150)
plt.close(figure)
if __name__ == "__main__":
plot_accuracy_comparison()
|
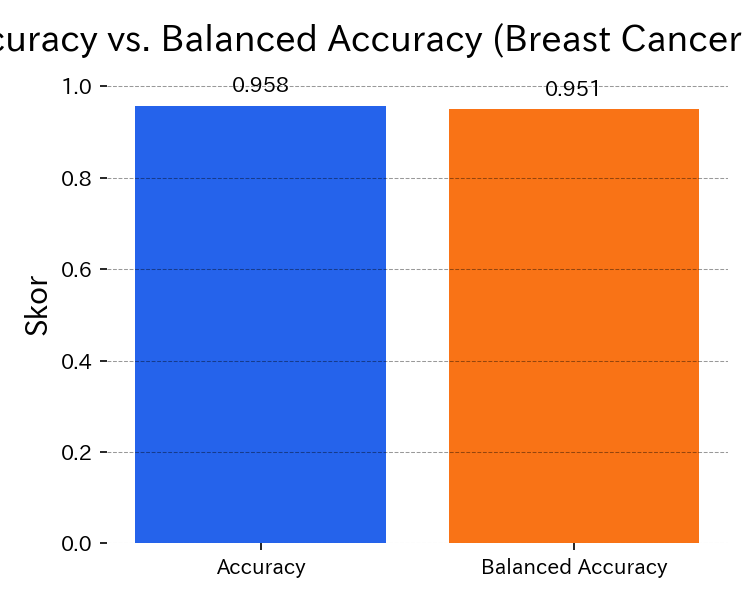
クラスが偏ると Balanced Accuracy での再評価が有効になるケースが多い
3. クラス不均衡への対処
#
Accuracy だけでは 少数クラスの識別性能が隠れてしまう ため、次の補助指標を併用しましょう。
- Precision / Recall / F1: 誤検知と見逃しのバランスを把握する。
- Balanced Accuracy: クラスごとの再現率を平均し偏りを補正する。
- Confusion Matrix: どのクラスでミスが多いかを視覚的に把握する。
- ROC-AUC / PR 曲線: 予測確率の評価と閾値調整の余地を探る。
Balanced Accuracy はクラスごとの再現率を平均した値で、少数クラスを重視したい場合の報告指標として有効です。
4. 現場でのチェックリスト
#
- ビジネス要件に合うか: 不均衡データで「Accuracy 99%」と言われても重要クラスを取りこぼしていないか混同行列で確認する。
- 閾値調整の余地はあるか: ROC-AUC や PR 曲線を併用し、閾値を変えた時の Accuracy の変化を把握する。
- 複数指標をセットで報告する: Accuracy と併せて Precision / Recall / F1 / Balanced Accuracy を揃えると偏りが可視化され、意思決定がしやすい。
- 再現可能なノートブックを用意する: Python 3.13 環境で動くノートブックを残し、モデル再学習のたびに同じ評価を素早く回せるようにする。
まとめ
#
- Accuracy は全体の当たり具合を手早く把握できる一方、クラス不均衡では過大評価に注意する。
- Python 3.13 + scikit-learn での実装では、
Pipeline と StandardScaler を活用すると安定した結果が得やすい。 - Balanced Accuracy や Precision / Recall と併せて評価し、モデルの癖やビジネスリスクに即した意思決定を支援しよう。
閾値と正解率
#
閾値に応じた正解率・バランス正解率の変化を確認できます。