4.3.10
Brier Score
- Brier Score は確率予測の平均二乗誤差を測るキャリブレーション指標です。
- 天気予報の確率を例に Brier Score と校正曲線の読み方を確認します。
- 確率の校正や Brier Skill Score と併用する際のポイントを整理します。
1. 定義 #
二値分類におけるブライアスコアは次式で表されます。
$$ \mathrm{Brier} = \frac{1}{n} \sum_{i=1}^{n} (p_i - y_i)^2 $$ここで \(p_i\) はモデルが出力した陽性確率、\(y_i\) は実際のラベル(0 または 1)です。多クラスでは各クラスに対して同様の誤差を求め、平均します。
2. Python 3.13 での計算と可視化 #
| |
以下のコードでは、乳がん診断データセットにロジスティック回帰を適用し、ブライアスコアと信頼度曲線を描画します。
| |
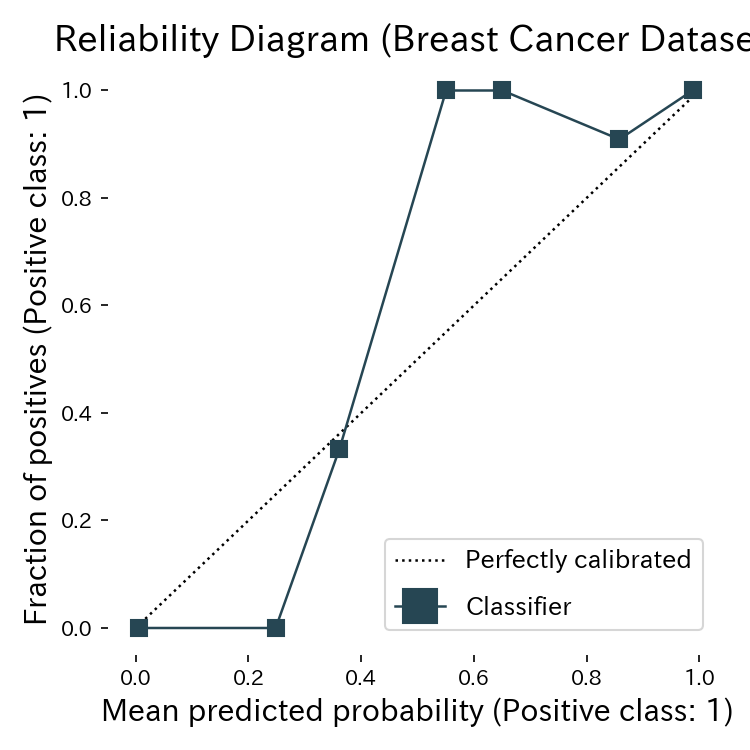
45 度線から外れているほど確率が過大・過小評価されているとわかる。
3. スコアの読み取り方 #
- 完全に正しい確率予測ではスコアが 0 になります。
- 常に 0.5 を返すモデルは、二値バランスで 0.25 を取るのが上限です。
- 値が小さいほど良く、確率を外し過ぎているモデルほどスコアが大きくなると覚えておきましょう。
4. キャリブレーション診断との併用 #
リライアビリティカーブ(信頼度曲線)は、予測確率をビンごとに平均し、実際の陽性率と比較した図です。
- 曲線が 45 度線より上 → 確率を控えめに出している(アンダーコンフィデント)。
- 曲線が 45 度線より下 → 確率を盛り過ぎている(オーバーコンフィデント)。
- CalibrationDisplay.from_predictions は等幅ビンでの可視化をサポートしており、ブライアスコアの変化と合わせて調整の効果を観察できます。 確率校正(Platt scaling や isotonic regression など)を適用した後に再度スコアと図を確認すると、キャリブレーション改善の有無が把握できます。
まとめ #
- ブライアスコアは確率予測の二乗誤差で、キャリブレーション評価に適した指標(小さいほど良い)。
- Python 3.13 + scikit-learn では brier_score_loss と信頼度曲線で簡単に診断可能。
- ROC-AUC や Precision/Recall などの閾値ベース評価と併用し、確率の正確さとランキング性能の両面からモデルを分析しよう。
閾値と Brier Score #
閾値に対する Brier Score の変化を確認できます。
よくある質問 #
Q: Brier Scoreの値はいくつなら「良い」? #
二値バランスクラスで常に0.5を予測するランダムモデルのスコアが0.25です。実用上は0.10以下で良好、0.05以下で非常に良好とされることが多いです。ただし問題の難しさに依存するため、Brier Skill Score(BSS = 1 − BS/BS_ref)でベースライン比の改善率を確認するのが安全です。
Q: ROC-AUCとBrier Scoreはどう使い分ける? #
ROC-AUCはモデルのランキング性能(陽性を上位に並べる力)を評価し、確率の絶対値は問いません。Brier Scoreは**確率の正確さ(キャリブレーション)**を評価します。「予測スコアの大小関係さえ正しければよい」場合はROC-AUC、「予測確率0.8は本当に80%の頻度で陽性になってほしい」場合はBrier Scoreが適しています。両指標を併用するのが理想的です。
Q: 多クラス分類でのBrier Scoreは? #
各クラス \(c\) に対して \(\frac{1}{n}\sum_i(p_{ic} - y_{ic})^2\) を計算し、クラス数で平均します。scikit-learnのbrier_score_lossは二値専用のため、多クラスではone-hotラベルと確率行列にmean_squared_errorを適用するか、手動で実装します。
Q: Log Loss(対数損失)と何が違う? #
Log Lossは予測確率の対数を取るため、高確信度で外れた予測を非常に厳しく罰します(「確率0.99」で外れると損失が急増)。Brier Scoreは二乗誤差なので罰則が相対的に緩やかです。Log Lossは情報量理論的な基盤があり確率が非常に重要なタスクに向いています。Brier Scoreは外れ値に頑健で値が直感的に解釈しやすい利点があります。
Q: キャリブレーションが悪い場合の対処法は? #
sklearn.calibration.CalibratedClassifierCVを使い、Plattスケーリング(method='sigmoid')またはIsotonic Regression(method='isotonic')で確率を補正できます。補正後に再度brier_score_lossと信頼度曲線を確認して改善を検証してください。一般的に、学習データが少ない場合はPlattスケーリング、多い場合はIsotonic Regressionが有利です。