まとめ- 混同行列は真陽性・偽陽性などの件数を整理して分類性能を可視化する表です。
- ロジスティック回帰の出力から混同行列を描画し、正規化表示も確認します。
- 多クラス対応や派生指標との関係など読み取りの注意点を整理します。
1. 混同行列の構造
#
二値分類の場合、混同行列は次の 2×2 表で表現します。
| 予測:陰性 | 予測:陽性 |
|---|
| 実際:陰性 | 真陰性 (TN) | 偽陽性 (FP) |
| 実際:陽性 | 偽陰性 (FN) | 真陽性 (TP) |
- 行は「実測クラス」、列は「モデルが予測したクラス」を意味します。
- TP・FP・FN・TN のバランスを見ることで、特定クラスに偏った判定をしていないかを確認できます。
2. Python 3.13 + scikit-learn での計算例
#
ローカル環境が Python 3.13 であることを想定し、バージョンと依存パッケージを確認しておきましょう。
1
2
| python --version # 例: Python 3.13.0
pip install scikit-learn matplotlib
|
下記スクリプトは乳がん診断データセットにロジスティック回帰を適用し、混同行列を計算・描画します。StandardScaler を挟むことで収束警告を避け、安定した結果を得やすくしています。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| from __future__ import annotations
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.preprocessing import StandardScaler
def build_pipeline(random_state: int = 42) -> Pipeline:
"""乳がん診断データを学習するロジスティック回帰パイプラインを構築する。"""
return make_pipeline(
StandardScaler(),
LogisticRegression(max_iter=1000, solver="lbfgs", random_state=random_state),
)
def run_example() -> None:
"""混同行列を計算し、数値と図で確認する。"""
features, labels = load_breast_cancer(return_X_y=True)
x_train, x_test, y_train, y_test = train_test_split(
features,
labels,
test_size=0.2,
stratify=labels,
random_state=42,
)
pipeline = build_pipeline()
pipeline.fit(x_train, y_train)
y_pred = pipeline.predict(x_test)
cm = confusion_matrix(y_test, y_pred)
print(cm)
display = ConfusionMatrixDisplay(confusion_matrix=cm)
display.plot(cmap="Blues", colorbar=False)
plt.tight_layout()
plt.show()
if __name__ == "__main__":
run_example()
|
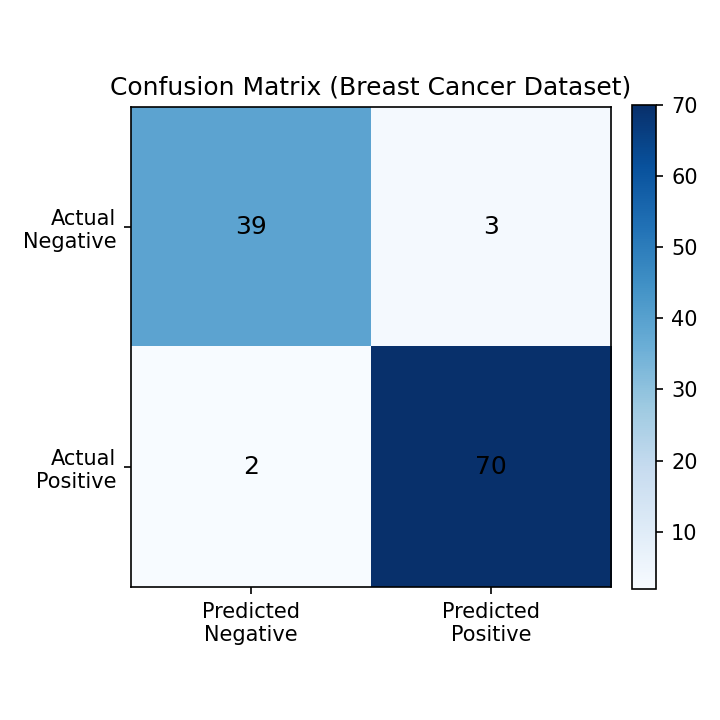
scikit-learn の Pipeline を用いて描画した混同行列
閾値と混同行列
#
分類閾値を変更すると、混同行列の各セルと派生指標がどう変化するか確認できます。
3. 正規化して割合を確認する
#
データにクラス不均衡がある場合は、行(実測クラス)ごとに割合を出すと読みやすくなります。
1
2
3
4
5
6
7
8
9
10
11
12
13
| from __future__ import annotations
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
def plot_normalized_matrix(y_true: np.ndarray, y_pred: np.ndarray) -> None:
"""正規化した混同行列を描画する。"""
matrix = confusion_matrix(y_true, y_pred, normalize="true")
display = ConfusionMatrixDisplay(confusion_matrix=matrix)
display.plot(cmap="Blues", values_format=".2f", colorbar=False)
plt.tight_layout()
plt.show()
|
normalize="true": 行ごとに正規化(実測クラスに対する割合)normalize="pred": 列ごとに正規化(予測クラスに対する割合)normalize="all": 全要素で正規化
4. 多クラス分類への拡張
#
多クラス分類でも ConfusionMatrixDisplay.from_predictions を用いれば同様に描画できます。ラベルは labels 引数または display_labels 引数で指定可能です。
1
2
3
4
5
6
7
8
9
| from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_predictions(
y_true=ground_truth_labels,
y_pred=model_outputs,
normalize="true",
values_format=".2f",
cmap="Blues",
)
|
5. 現場でのチェックポイント
#
- 偽陰性と偽陽性のトレードオフ: 医療・不正検知などでは、どちらを最小化したいのかを明確にしたうえで混同行列をチェックします。
- ヒートマップでの共有: グラフ化すると偏りが直感的にわかり、チーム内での議論がスムーズになります。
- 派生指標との連携: 混同行列から算出できる精度・適合率・再現率・F1 を ROC-AUC や PR 曲線と併用し、全体像を把握しましょう。
- ノートブックの再利用: Python 3.13 環境で再現可能なノートブックを用意しておくと、モデル改善サイクルを高速に回せます。
まとめ
#
- 混同行列は TP・FP・FN・TN を整理し、モデルの癖を素早く把握できる評価表です。
normalize オプションで割合を出せば、クラス不均衡でも比較しやすくなります。- 可視化した混同行列と派生メトリクスを組み合わせ、ビジネス要件に沿った評価基準を設計しましょう。