4.3.4
Log Loss
まとめ
- Log Loss は確率予測の対数損失を平均した指標で予測確率の信頼性を評価します。
- 確率出力モデルで Log Loss を算出し、極端なしきい値による悪化を確認します。
- 確率校正やラベルスムージングを行う際の注意点を整理します。
1. 定義 #
二値分類の Log Loss は次式で表されます。
$$ \mathrm{LogLoss} = -\frac{1}{n} \sum_{i=1}^{n} \left[ y_i \log(p_i) + (1 - y_i) \log(1 - p_i) \right] $$ここで \(p_i\) は陽性クラスの予測確率、\(y_i\) は正解ラベル(0 または 1)です。多クラスでは各クラスの確率とワンホットラベルの積を同様に加算します。
2. Python 3.13 での計算 #
| |
| |
predict_proba が返す確率を log_loss に渡すだけで評価できます。
3. ペナルティのイメージ #
推定確率が真のラベルとズレるほど Log Loss は急激に増えます。 実際のラベルが 1 のときは −log(p)、0 のときは −log(1−p) がペナルティになる。確率を外すほど急増する。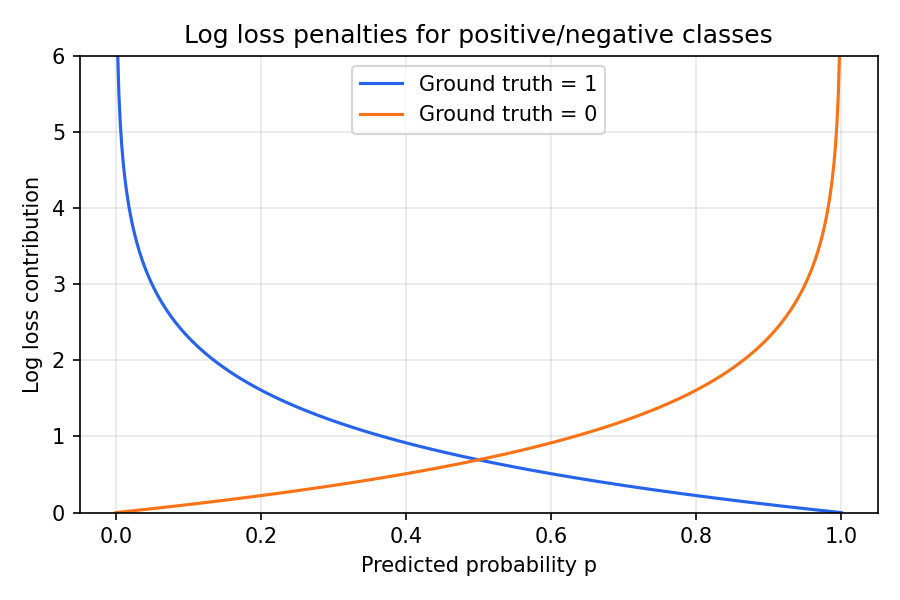
- 陽性サンプルに低い確率(例: 0.1)を付与すると大きく罰せられます。
- 0.5 のような無難な確率ばかりでは、検出性能が低いと判断されます。
4. 実務での使いどころ #
- キャリブレーションの確認 — Platt scaling や isotonic regression で補正したあとの効果測定に最適。
- コンペティション — Kaggle など確率を評価するコンテストで採用されることが多い指標。
- 閾値に依存しない比較 — Accuracy のように閾値固定ではないため、ランキング性能や確率の信頼性をまとめて評価できます。 scikit-learn の log_loss には labels, eps, ormalize などの引数があり、欠損ラベルや数値の安定性に配慮できます。
まとめ #
- Log Loss は確率予測の「どれだけ自信を外したか」を測る指標。小さいほど良い。
- Python 3.13 では log_loss と predict_proba で簡単に算出できる。
- Accuracy や ROC-AUC だけでなく、Log Loss で確率の品質を併せて確認しよう。
閾値と各指標の変化 #
閾値を動かすと Accuracy や F1 は大きく変動しますが、Log Loss は確率そのもので計算するため閾値に依存しません。この性質が Log Loss の特徴です。
- ブライアスコア — 予測確率の校正を二乗誤差で評価
- ROC-AUC — 閾値非依存のランキング性能
- 平均適合率 — PR 曲線ベースの総合評価
- Focal Loss — Log Lossを拡張した不均衡データ向け損失関数