4.4.1
Kullback-Leibler ダイバージェンス
まとめ
- KL ダイバージェンスは「基準分布に対してどれだけ情報量が増えるか」を測る指標です。
- 離散分布の例で計算手順とゼロ確率に対するスムージング方法を確認します。
- 生成モデル評価やモニタリングで活用する際の注意点を整理します。
1. KL ダイバージェンスとは #
KL ダイバージェンスは、基準分布 \(Q\) を想定したときに実際の分布 \(P\) がどれだけ異なるかを相対エントロピーとして表します。
$$ \mathrm{KL}(P \parallel Q) = \sum_i p_i \log \frac{p_i}{q_i} $$- \(\mathrm{KL}(P \parallel Q) = 0\) のとき、分布は一致します。
- 非対称性を持ち、一般に \(\mathrm{KL}(P \parallel Q) \neq \mathrm{KL}(Q \parallel P)\) です。
- \(q_i = 0\) かつ \(p_i > 0\) の場合は無限大となるため、サポートの違いに敏感です。
2. Python での基本実装 #
| |
rel_entr を用いると、配列要素ごとの \(p_i \log \frac{p_i}{q_i}\) を安全に計算できます。ゼロ確率が含まれる場合は微小値 \(\epsilon\) を加えるなどのスムージングを事前に行いましょう。
3. ヒストグラム例での比較 #
以下は 2 つの離散分布(棒グラフ)を比較した例です。
| |
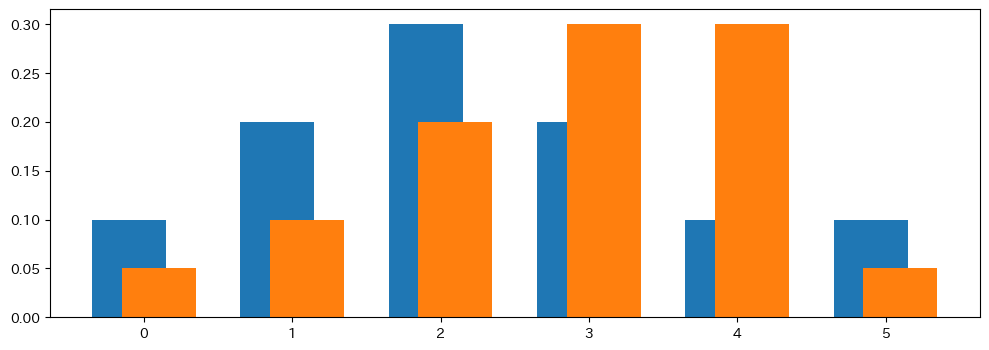
分布pとqを棒グラフで並べた例。形状の違いがKLダイバージェンスの大きさに反映される。
同じ観測値から得られた分布を比較すると、KL は 0 になります。
| |
結果が示すように、順序を入れ替えると値が変わるため、どちらを基準とするかで解釈が異なります。
4. Jensen–Shannon ダイバージェンスへの接続 #
KL の非対称性を解消したい場合は、両方向の KL を平均した Jensen–Shannon ダイバージェンスを用います。以下の図は 2 つの正規分布とその平均分布のイメージです。
| |
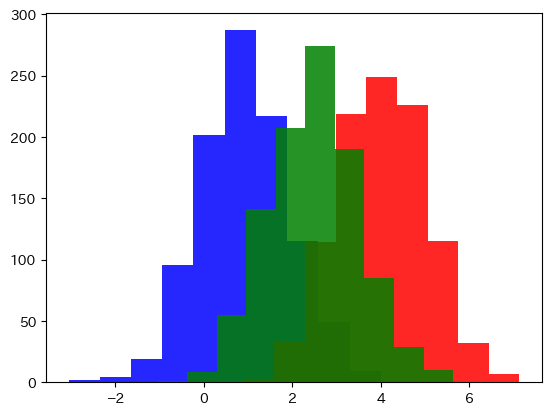
青と赤の正規分布の中間(緑)を基準にすると、Jensen-Shannonダイバージェンスが計算できる。
5. 実務での活用例と注意点 #
- 生成モデル評価:生成分布が教師データから離れていないかをチェック。
- 監視・ドリフト検知:配信データが学習時分布からどれだけ乖離しているかをモニタリング。
- 言語モデル:n-gram 分布や出力確率の差異を測定。
注意点として、サンプル数が少ない場合は推定が不安定になるため、ディリクレ事前分布によるスムージングなどを組み合わせます。また、距離が大きい場合でも必ずしも性能悪化を意味しないため、他の指標と合わせて解釈しましょう。
まとめ #
KL ダイバージェンスは「基準分布との相対的な情報量差」を表し、モデルの評価や監視で広く利用されます。非対称性やゼロ確率への感度といった性質を理解し、適切なスムージングと併せて活用してください。
- Jensen-Shannon ダイバージェンス — KLD の対称化版
- ヘリンガー距離 — 分布間距離の別指標
- コサイン類似度 — ベクトル空間での類似度
- PSI — KLダイバージェンスを応用したデータドリフト検出指標
分布の差と KL ダイバージェンス #
2 つの分布の差を変えると KL ダイバージェンスがどう変化するか確認できます。