4.1.5
ラーニングカーブ(Learning Curve)
まとめ
- Learning Curve は学習データ量とモデルスコアの関係を可視化する診断手法です。
learning_curveを使ってサンプル数ごとの訓練・検証スコアを描画し、バイアスやバリアンスの兆候を確認します。- データ収集やモデル調整の意思決定に生かす読み方と注意点を整理します。
- 交差検証 の概念を先に学ぶと理解がスムーズです
1. Learning Curve とは #
Learning Curve(学習曲線)は、学習に用いるサンプル数を徐々に増やした際の 訓練スコア と 検証スコア を並べたグラフです。次のような問いに答えるのに役立ちます。
- モデルが表現力不足(高バイアス)か、もしくは学習しすぎ(高バリアンス)か。
- 追加でデータを集めた場合、性能が向上する余地があるか。
- ハイパーパラメータやモデル構造を見直すべきかどうか。
2. Python 3.13 での例 #
下記のスクリプトでは回帰問題を題材に、Ridge 回帰の Learning Curve を描画します。
| |
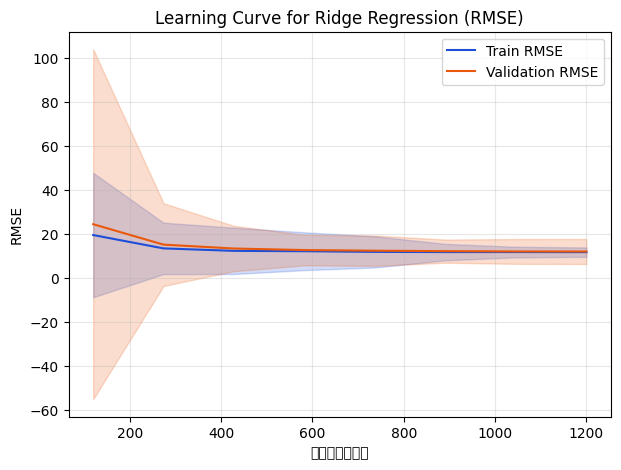
サンプル数を増やすと訓練 RMSE が徐々に悪化し、検証 RMSE と近づく。十分なデータ量では検証スコアが安定し、これ以上のデータ追加効果が小さいことがわかる。
3. グラフの読み取り #
- 高バリアンス(過学習)の兆候:訓練スコアは非常に良い一方で検証スコアが離れている。ハイパーパラメータを強める・特徴量を減らす・データを増やすなどで改善を図る。
- 高バイアス(学習不足)の兆候:訓練スコアも検証スコアも悪い。モデルを複雑にする、特徴量を増やす、表現力の高いアルゴリズムへ変更する等が検討事項。
- 収束している状態:訓練・検証スコアが近づき、追加データを入れても大きく改善しない。別のモデルや特徴量設計を試すタイミング。
4. 実務での活用ポイント #
- データ収集の投資判断:Learning Curve がまだ下降中であれば追加データの価値が高い。収束していれば別施策に工数を割り当てる。
- モデル容量・正則化の調整:曲線を確認してから木の深さや正則化強度を調整すると、過学習と学習不足を効率的に切り分けられる。
- 特徴量エンジニアリングの優先度:訓練・検証スコアが高い位置で平行に走っている場合は、特徴量の改善が必要なサイン。
- 他の診断ツールとの併用:Validation Curve や検証スコアの時系列と組み合わせると、改善サイクルの方向性を議論しやすくなる。
まとめ #
- Learning Curve は訓練・検証スコアをサンプル数に対してプロットし、過学習・学習不足を見分ける。
learning_curve関数を使えば簡単に図を生成でき、追加データやモデル調整の意思決定を後押しする。- その他の診断手法と併用しつつ、データとモデルのバランスを継続的にチェックしよう。
推定器数と学習 #
推定器数を増やすと訓練誤差・テスト誤差がどう変化するか確認できます。