まとめ Stratified K-Foldは各フォールドでクラス比率を維持する交差検証法です。 不均衡データでStratifiedと通常のK-Foldを比較し、偏りの違いを可視化します。 クラス比率が極端な場合の分割設計や実装上の注意点を整理します。 1. Stratified K-Foldとは
# 通常のK-Foldはデータをランダムに分割するため、クラス不均衡なデータでは一部のフォールドに少数クラスのサンプルが偏る(または含まれない)ことがある。Stratified K-Foldは各フォールドで元データのクラス比率を維持するように分割することで、この問題を防ぐ。
通常のK-Fold : ランダム分割。ラベル比率が崩れる可能性がある。Stratified K-Fold : 各フォールドのラベル比率を元データと同じに保つ。分類タスクでは基本的にこちらを使う。2. Pythonでの比較実験
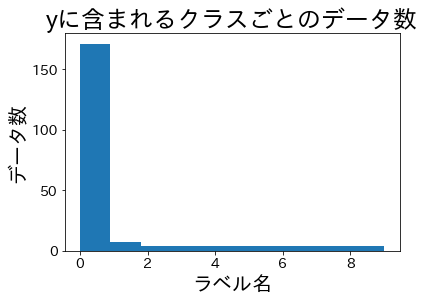
# 10クラスの不均衡データ(クラス0が82%を占める)を生成し、通常のK-FoldとStratified K-Foldで分割した場合のラベル分布を比較します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from __future__ import annotations
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import KFold , StratifiedKFold
RANDOM_STATE = 42
N_CLASSES = 10
X , y = make_classification (
n_samples = 210 ,
n_classes = N_CLASSES ,
n_informative = N_CLASSES ,
n_features = 12 ,
n_clusters_per_class = 1 ,
weights = [ 0.82 , 0.02 , 0.02 , 0.02 , 0.02 , 0.02 , 0.02 , 0.02 , 0.02 , 0.02 ],
random_state = RANDOM_STATE ,
)
元データのクラス分布
# 1
2
3
4
5
6
7
fig , ax = plt . subplots ( figsize = ( 6 , 3 ))
ax . hist ( y , bins = N_CLASSES , color = "#2563eb" , edgecolor = "white" )
ax . set_xlabel ( "Class label" )
ax . set_ylabel ( "Count" )
ax . set_title ( "Class distribution in full dataset" )
ax . grid ( alpha = 0.3 )
plt . tight_layout ()
クラス0が大多数を占める不均衡データ。少数クラスはそれぞれ数件しかない。
Stratified K-Foldによる分割
# 各フォールドで訓練データと検証データのラベル比率が維持されていることを確認します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
skf = StratifiedKFold ( n_splits = 4 , shuffle = True , random_state = RANDOM_STATE )
fig , axes = plt . subplots ( 4 , 2 , figsize = ( 8 , 8 ))
for i , ( train_idx , valid_idx ) in enumerate ( skf . split ( X , y )):
y_train , y_valid = y [ train_idx ], y [ valid_idx ]
axes [ i , 0 ] . bar (
range ( N_CLASSES ),
[( y_train == c ) . sum () for c in range ( N_CLASSES )],
color = "#2563eb" ,
)
axes [ i , 0 ] . set_title ( f "Fold { i + 1 } : Train" )
axes [ i , 1 ] . bar (
range ( N_CLASSES ),
[( y_valid == c ) . sum () for c in range ( N_CLASSES )],
color = "#f97316" ,
)
axes [ i , 1 ] . set_title ( f "Fold { i + 1 } : Valid" )
plt . tight_layout ()
Stratified K-Fold: すべてのフォールドで訓練・検証データのクラス比率が元データと一致している。
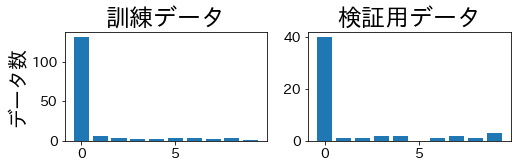
通常のK-Foldによる分割
# 一部のフォールドで少数クラスが検証データに含まれていないことが確認できます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
kf = KFold ( n_splits = 4 )
fig , axes = plt . subplots ( 4 , 2 , figsize = ( 8 , 8 ))
for i , ( train_idx , valid_idx ) in enumerate ( kf . split ( X , y )):
y_train , y_valid = y [ train_idx ], y [ valid_idx ]
axes [ i , 0 ] . bar (
range ( N_CLASSES ),
[( y_train == c ) . sum () for c in range ( N_CLASSES )],
color = "#2563eb" ,
)
axes [ i , 0 ] . set_title ( f "Fold { i + 1 } : Train" )
axes [ i , 1 ] . bar (
range ( N_CLASSES ),
[( y_valid == c ) . sum () for c in range ( N_CLASSES )],
color = "#f97316" ,
)
axes [ i , 1 ] . set_title ( f "Fold { i + 1 } : Valid" )
plt . tight_layout ()
通常のK-Fold: フォールドによっては検証データに少数クラスが含まれず、評価が不安定になる。
3. 使い分けのポイント
# 分類タスクではStratified K-Foldを標準とする 。scikit-learnのcross_val_scoreは分類時にデフォルトでStratifiedKFoldを使用する。回帰タスク ではラベルが連続値のため通常のK-Foldを使う。目的変数の分布に偏りがある場合はビニングしてStratifiedKFoldに渡す方法もある。極端な不均衡 (少数クラスがフォールド数より少ない場合)ではRepeatedStratifiedKFoldで分割を繰り返し、安定したスコアを得る。4. 実務でのチェックリスト
# 各フォールドの訓練・検証データにすべてのクラスが含まれているか確認したか shuffle=Trueとrandom_stateを設定し、再現性を確保しているか時系列データの場合はTimeSeriesSplitを優先し、Stratifiedは使わない まとめ
# Stratified K-Foldは各フォールドでクラス比率を維持し、不均衡データでの評価を安定させる。 分類タスクでは標準的にStratifiedを使い、通常のK-Foldはラベル偏りが生じるリスクがある。 フォールド数と少数クラスのサンプル数の関係を事前に確認し、適切な分割戦略を設計しよう。 分割数と層化 k 分割
# 分割数 k を変えると各フォールドのサイズがどう変わるか確認できます。