まとめ- レーダーチャートで複数の財務指標を正多角形上にプロットし、企業間の総合力を視覚比較する。
- matplotlibの極座標プロット(polar)を使い、EPS・売上・配当などの多軸データを描画する。
- スコアの正規化や方向の統一により、公平な比較が可能なチャートを作成する。
直感
#
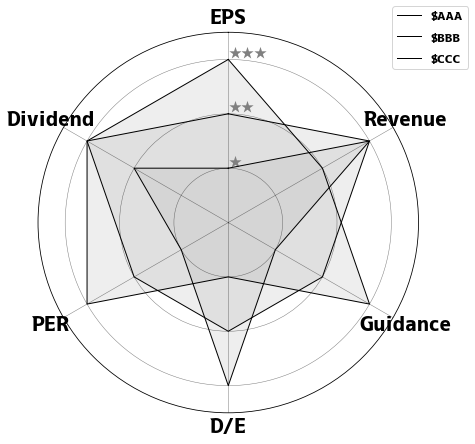
レーダーチャートは複数の項目をまとめて比較する方法のひとつです。複数の項目がバランスよく高い値か、低い値かを確認するときに役に立ちます。財務分析では、EPS・売上成長率・配当利回り・負債比率など異なる次元の指標を1つのグラフで俯瞰できるため、銘柄選定や競合比較のスクリーニングに活用されます。
すべての項目を「高ければ高いほど良い」状態に統一するのがポイントです。たとえばD/Eレシオ(負債比率)は低いほど良いため、逆数やランキングに変換してからプロットします。
詳細な解説
#
サンプルデータの準備
#
3銘柄の財務指標をスコア化(1〜3の評価)したデータを作成します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from math import pi
df = pd.DataFrame(
index=["$AAA", "$BBB", "$CCC"],
data={
"EPS": [1, 2, 3],
"Revenue": [3, 3, 2],
"Guidance": [1, 2, 3],
"D/E": [3, 2, 1],
"PER": [1, 2, 3],
"Dividend": [2, 3, 3],
},
)
print(df)
|
レーダーチャートのプロット
#
matplotlibの極座標プロット(polar=True)を使い、各指標を正多角形の頂点に配置します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| plt.figure(figsize=(7, 7))
ax = plt.subplot(111, polar=True)
ax.set_theta_offset(pi / 2.0)
ax.set_theta_direction(-1)
# 各ラベルの位置調整
angles = [2 * n * pi / len(df.columns) for n in range(len((df.columns)))]
plt.xticks(angles, df.columns, size=20)
ax.set_rlabel_position(0)
plt.yticks([1, 2, 3], ["★", "★★", "★★★"], color="grey", size=13)
plt.ylim(0, 3.5)
# 指定範囲の塗りつぶし
for ticker_symbol in ["$AAA", "$BBB", "$CCC"]:
values = df.loc[ticker_symbol].values.flatten().tolist()
ax.plot(
angles + [0],
values + [values[0]],
linewidth=1,
linestyle="solid",
c="#000",
label=ticker_symbol,
)
ax.fill(angles + [0], values + [values[0]], "#aaa", alpha=0.2)
plt.legend(bbox_to_anchor=(0.9, 1.1))
plt.show()
|
銘柄ごとに色分けする改良版
#
銘柄ごとに異なる色で塗り分けると、どの企業がどの指標で優位かが明確になります。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| colors = ["#3b82f6", "#10b981", "#f59e0b"]
fig, ax = plt.subplots(figsize=(7, 7), subplot_kw={"polar": True})
ax.set_theta_offset(pi / 2.0)
ax.set_theta_direction(-1)
ax.set_rlabel_position(0)
plt.xticks(angles, df.columns, size=16)
plt.yticks([1, 2, 3], ["1", "2", "3"], color="grey", size=11)
plt.ylim(0, 3.5)
for (ticker, row), color in zip(df.iterrows(), colors):
values = row.values.flatten().tolist()
ax.plot(angles + [0], values + [values[0]], linewidth=2, color=color, label=ticker)
ax.fill(angles + [0], values + [values[0]], color=color, alpha=0.15)
plt.legend(loc="upper right", bbox_to_anchor=(1.15, 1.1))
plt.title("銘柄別 財務スコア比較", y=1.08, fontsize=14)
plt.show()
|
総合スコアの算出
#
レーダーチャートの面積に相当する総合スコアを数値化すると、ランキングの根拠を定量的に示せます。
1
2
3
4
5
6
7
8
9
10
11
12
13
| def radar_area(values: list) -> float:
"""レーダーチャートの多角形面積を計算"""
n = len(values)
theta = 2 * pi / n
area = 0.5 * sum(
values[i] * values[(i + 1) % n] * np.sin(theta)
for i in range(n)
)
return abs(area)
for ticker in df.index:
vals = df.loc[ticker].values.tolist()
print(f"{ticker}: 総合スコア(面積) = {radar_area(vals):.2f}")
|
分析のヒント
#
- 指標のスケールが異なる場合(EPS: 0〜10、PER: 5〜30など)は、Min-Max正規化やパーセンタイルランクで0〜1に揃えてからプロットします。
- 「低いほど良い」指標(PER、D/Eレシオなど)は値を反転させるか、ランキングに変換して方向を統一します。
- 銘柄数が多い場合はレーダーチャートが見づらくなるため、4銘柄程度までに絞るか、サブプロットで分割します。
- セクター平均をベースラインとして描き加えると、各銘柄の相対的な強みがより明確になります。