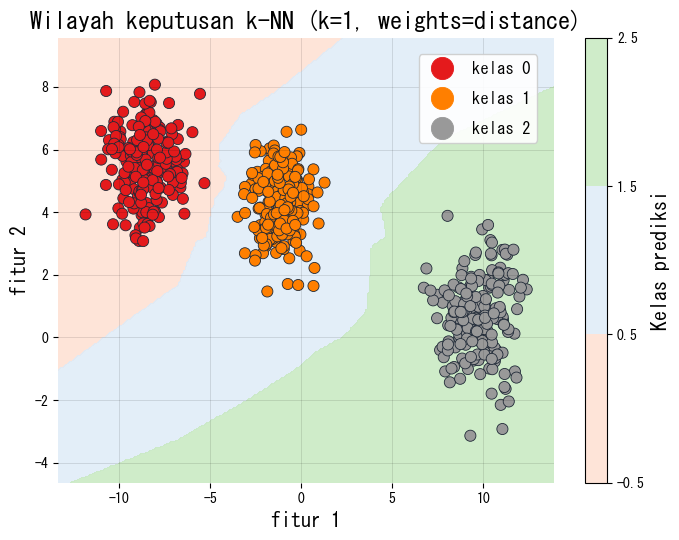
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
| from __future__ import annotations
import japanize_matplotlib
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.colors import ListedColormap
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
def run_knn_demo(
n_samples: int = 600,
random_state: int = 7,
weights: str = "distance",
k_values: tuple[int, ...] = (1, 3, 5, 7, 11),
validation_ratio: float = 0.3,
title: str = "Wilayah keputusan k-NN",
xlabel: str = "fitur 1",
ylabel: str = "fitur 2",
class_label_prefix: str = "kelas",
) -> dict[str, object]:
"""Evaluate k-NN for several neighbour counts and plot decision regions.
Args:
n_samples: Number of synthetic samples to draw.
random_state: Seed for reproducible sampling.
weights: Weighting scheme handed to KNeighborsClassifier.
k_values: Candidate neighbour counts to evaluate.
validation_ratio: Fraction of the data reserved for validation.
title: Title for the generated figure.
xlabel: Label for the x-axis.
ylabel: Label for the y-axis.
class_label_prefix: Prefix used when labelling the classes.
Returns:
Dictionary with validation scores per k and the best-performing k.
"""
japanize_matplotlib.japanize()
X, y = make_blobs(
n_samples=n_samples,
centers=3,
cluster_std=[1.1, 1.0, 1.2],
random_state=random_state,
)
rng = np.random.default_rng(random_state)
indices = rng.permutation(len(X))
split = int(len(X) * (1.0 - validation_ratio))
train_idx, valid_idx = indices[:split], indices[split:]
X_train, X_valid = X[train_idx], X[valid_idx]
y_train, y_valid = y[train_idx], y[valid_idx]
scores: dict[int, float] = {}
for k in k_values:
model = make_pipeline(
StandardScaler(),
KNeighborsClassifier(n_neighbors=k, weights=weights),
)
model.fit(X_train, y_train)
scores[k] = float(model.score(X_valid, y_valid))
best_k = max(scores, key=scores.get)
best_model = make_pipeline(
StandardScaler(),
KNeighborsClassifier(n_neighbors=best_k, weights=weights),
)
best_model.fit(X, y)
xx, yy = np.meshgrid(
np.linspace(X[:, 0].min() - 1.5, X[:, 0].max() + 1.5, 300),
np.linspace(X[:, 1].min() - 1.5, X[:, 1].max() + 1.5, 300),
)
grid = np.column_stack([xx.ravel(), yy.ravel()])
predictions = best_model.predict(grid).reshape(xx.shape)
unique_classes = np.unique(y)
levels = np.arange(unique_classes.min(), unique_classes.max() + 2) - 0.5
cmap = ListedColormap(["#fee0d2", "#deebf7", "#c7e9c0"])
fig, ax = plt.subplots(figsize=(7, 5.5))
contour = ax.contourf(xx, yy, predictions, levels=levels, cmap=cmap, alpha=0.85)
scatter = ax.scatter(
X[:, 0],
X[:, 1],
c=y,
cmap="Set1",
edgecolor="#1f2937",
linewidth=0.6,
)
ax.set_title(f"{title} (k={best_k}, weights={weights})")
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.grid(alpha=0.15)
legend = ax.legend(
handles=scatter.legend_elements()[0],
labels=[f"{class_label_prefix} {cls}" for cls in unique_classes],
loc="upper right",
frameon=True,
)
legend.get_frame().set_alpha(0.9)
fig.colorbar(contour, ax=ax, label="Kelas prediksi")
fig.tight_layout()
plt.show()
return {"scores": scores, "best_k": int(best_k), "validation_accuracy": scores[best_k]}
metrics = run_knn_demo(
title="Wilayah keputusan k-NN",
xlabel="fitur 1",
ylabel="fitur 2",
class_label_prefix="kelas",
)
print(f"k terbaik: {metrics['best_k']}")
print(f"Akurasi validasi (k terbaik): {metrics['validation_accuracy']:.3f}")
for candidate_k, score in metrics["scores"].items():
print(f"k={candidate_k}: akurasi validasi={score:.3f}")
|