2.2.4
Linear Discriminant Analysis (LDA)
Ringkasan
- LDA mencari arah yang memaksimalkan rasio antara variansi antar kelas dan variansi intra kelas, sehingga berguna untuk klasifikasi sekaligus reduksi dimensi.
- Batas keputusan berbentuk \(\mathbf{w}^\top \mathbf{x} + b = 0\); di 2D berupa garis dan di 3D berupa bidang, mudah ditafsirkan secara geometris.
- Dengan asumsi tiap kelas berdistribusi Gaussian dan berbagi kovarians yang sama, LDA mendekati klasifikator Bayes optimal.
LinearDiscriminantAnalysisdi scikit-learn memudahkan visualisasi batas keputusan dan inspeksi fitur hasil proyeksi.
Intuisi #
Metode ini dipahami lewat asumsi dasarnya, karakteristik data, dan dampak pengaturan parameter terhadap generalisasi.
Penjelasan Rinci #
Formulasi matematis #
Untuk dua kelas, arah proyeksi \(\mathbf{w}\) memaksimalkan
$$ J(\mathbf{w}) = \frac{\mathbf{w}^\top \mathbf{S}_B \mathbf{w}}{\mathbf{w}^\top \mathbf{S}_W \mathbf{w}}, $$di mana \(\mathbf{S}_B\) adalah matriks sebar antar kelas dan \(\mathbf{S}_W\) adalah matriks sebar intra kelas. Pada kasus multikelas diperoleh hingga \(K-1\) arah proyeksi yang berguna untuk reduksi dimensi.
Eksperimen dengan Python #
Contoh berikut menerapkan LDA pada data sintetis dua kelas, menggambar batas keputusan, dan menampilkan fitur hasil proyeksi 1D. Dengan transform, data hasil proyeksi dapat langsung diperoleh.
| |
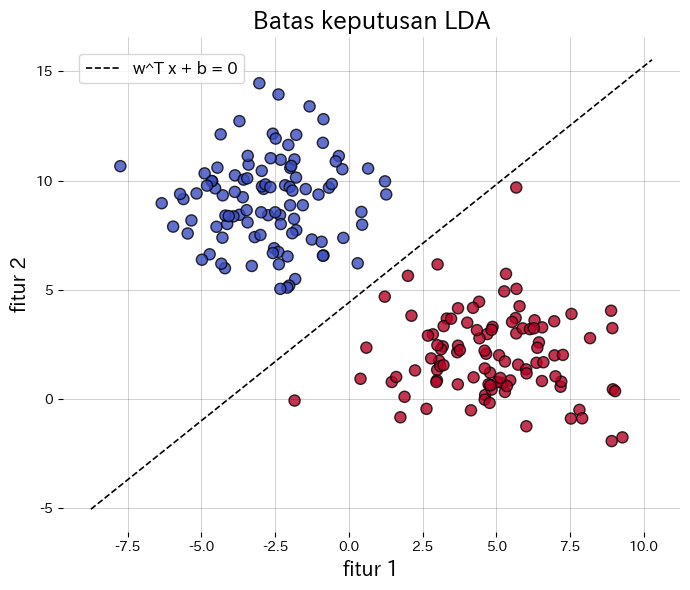
Referensi #
- Fisher, R. A. (1936). The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7(2), 179–188.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.