2.2.1
Regresi logistik
Ringkasan
- Regresi logistik memasukkan kombinasi linear fitur ke fungsi sigmoid untuk memperkirakan probabilitas bahwa label bernilai 1.
- Keluaran berada di rentang \([0, 1]\), sehingga ambang keputusan dapat diatur fleksibel dan koefisien dapat dibaca sebagai kontribusi terhadap log-odds.
- Pelatihan meminimalkan loss entropi silang (sama dengan memaksimalkan log-likelihood); regularisasi L1/L2 membantu menekan overfitting.
- Dengan
LogisticRegressiondari scikit-learn, pra-pemrosesan, pelatihan, hingga visualisasi garis keputusan dapat diselesaikan dalam beberapa baris kode.
Intuisi #
Metode ini dipahami lewat asumsi dasarnya, karakteristik data, dan dampak pengaturan parameter terhadap generalisasi.
Penjelasan Rinci #
Formulasi matematis #
Probabilitas kelas 1 diberikan oleh
$$ P(y=1 \mid \mathbf{x}) = \sigma(\mathbf{w}^\top \mathbf{x} + b) = \frac{1}{1 + \exp\left(-(\mathbf{w}^\top \mathbf{x} + b)\right)}. $$Model dilatih dengan memaksimalkan log-likelihood
$$ \ell(\mathbf{w}, b) = \sum_{i=1}^{n} \Bigl[ y_i \log p_i + (1 - y_i) \log (1 - p_i) \Bigr], \quad p_i = \sigma(\mathbf{w}^\top \mathbf{x}_i + b), $$atau, secara ekuivalen, meminimalkan entropi silang negatif. Regularisasi L2 menahan koefisien agar tidak terlalu besar, sedangkan L1 dapat meniadakan fitur yang tidak relevan.
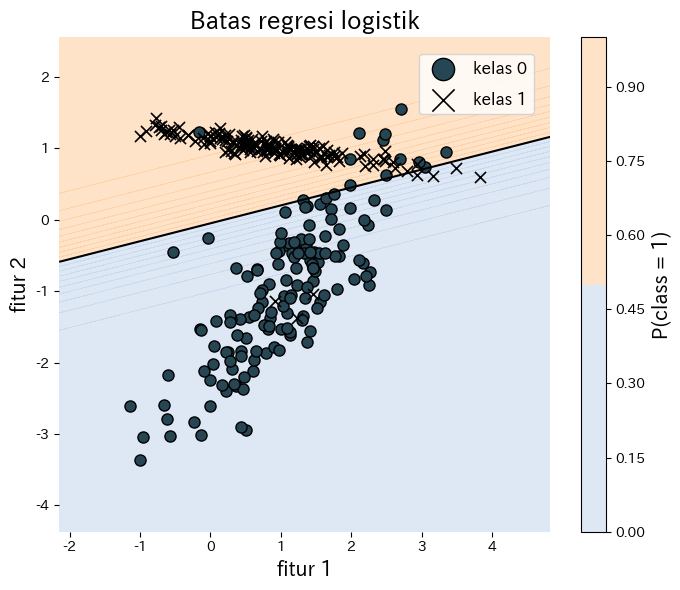
Eksperimen dengan Python #
Contoh berikut menyesuaikan regresi logistik pada data sintetis dua dimensi dan memvisualisasikan garis keputusan yang dihasilkan. Berkat scikit-learn, seluruh proses pelatihan dan plotting hanya membutuhkan sedikit kode.
| |
Referensi #
- Agresti, A. (2015). Foundations of Linear and Generalized Linear Models. Wiley.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.