2.2.3
Perceptron
Ringkasan
- Perceptron akan konvergen dalam jumlah pembaruan terbatas jika data dapat dipisahkan secara linear, menjadikannya salah satu algoritme klasifikasi tertua.
- Prediksi menggunakan tanda \(\mathbf{w}^\top \mathbf{x} + b\); jika tanda salah, sampel tersebut memperbarui bobot.
- Aturan pembaruan—menambahkan sampel yang salah diklasifikasikan dikalikan laju belajar—memberikan intuisi awal untuk metode berbasis gradien.
- Jika data tidak dapat dipisahkan secara linear, perluasan fitur atau kernel trick menjadi solusi.
Intuisi #
Metode ini dipahami lewat asumsi dasarnya, karakteristik data, dan dampak pengaturan parameter terhadap generalisasi.
Penjelasan Rinci #
Formulasi matematis #
Prediksi dihitung sebagai
$$ \hat{y} = \operatorname{sign}(\mathbf{w}^\top \mathbf{x} + b). $$Jika contoh \((\mathbf{x}_i, y_i)\) salah klasifikasi, perbarui parameter dengan
$$ \mathbf{w} \leftarrow \mathbf{w} + \eta\, y_i\, \mathbf{x}_i,\qquad b \leftarrow b + \eta\, y_i. $$Untuk data yang terpisahkan secara linear, prosedur ini dijamin konvergen.
Eksperimen dengan Python #
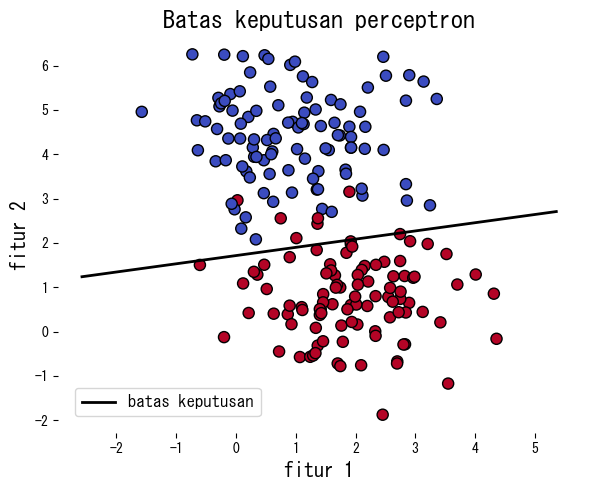
Contoh berikut menerapkan perceptron pada data sintetis, melaporkan jumlah kesalahan per epoch, dan menggambar batas keputusan yang dihasilkan.
| |
Referensi #
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, 65(6), 386–408.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.