2.2.5
Support Vector Machine (SVM)
Ringkasan
- SVM mempelajari batas keputusan yang memaksimalkan margin antar kelas, sehingga menekankan kemampuan generalisasi.
- Margin lunak memperkenalkan variabel slack; parameter \(C\) mengatur kompromi antara lebar margin dan jumlah kesalahan yang diizinkan.
- Kernel trick mengganti hasil kali dalam dengan fungsi kernel, memungkinkan batas keputusan nonlinier tanpa ekspansi fitur eksplisit.
- Penyetaraan fitur dan pencarian hiperparameter (\(C\), \(\gamma\), dsb.) penting untuk kinerja yang baik.
Intuisi #
Metode ini dipahami lewat asumsi dasarnya, karakteristik data, dan dampak pengaturan parameter terhadap generalisasi.
Penjelasan Rinci #
Formulasi matematis #
Untuk data yang dapat dipisahkan secara linear, kita menyelesaikan
$$ \min_{\mathbf{w}, b} \ \frac{1}{2} \lVert \mathbf{w} \rVert_2^2 \quad \text{s.t.} \quad y_i(\mathbf{w}^\top \mathbf{x}_i + b) \ge 1. $$Pada praktiknya digunakan SVM margin lunak dengan variabel slack \(\xi_i \ge 0\):
$$ \min_{\mathbf{w}, b, \boldsymbol{\xi}} \ \frac{1}{2} \lVert \mathbf{w} \rVert_2^2 + C \sum_{i=1}^{n} \xi_i \quad \text{s.t.} \quad y_i(\mathbf{w}^\top \mathbf{x}_i + b) \ge 1 - \xi_i. $$Mengganti hasil kali \(\mathbf{x}_i^\top \mathbf{x}_j\) dengan kernel \(K(\mathbf{x}_i, \mathbf{x}_j)\) memungkinkan batas keputusan nonlinier.
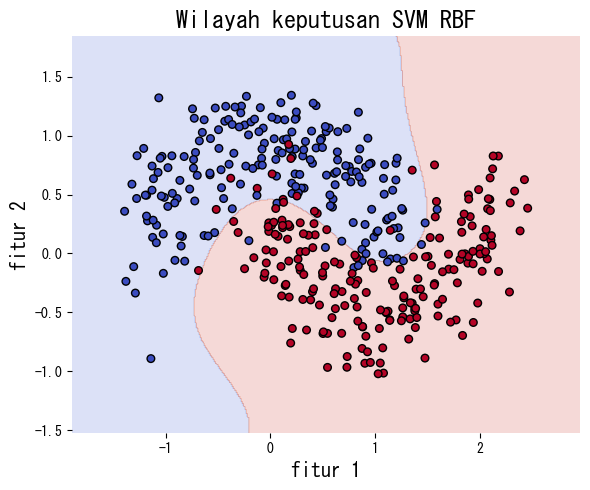
Eksperimen dengan Python #
Cuplikan berikut melatih SVM dengan kernel linear dan kernel RBF pada data make_moons yang tidak separabel secara linear. Kernel RBF jauh lebih mampu menangkap batas melengkung.
| |
Referensi #
- Vapnik, V. (1998). Statistical Learning Theory. Wiley.
- Smola, A. J., & Schölkopf, B. (2004). A Tutorial on Support Vector Regression. Statistics and Computing, 14(3), 199–222.