2.5.5
Gaussian Mixture Model (GMM)
Ringkasan
- GMM memodelkan data sebagai gabungan berbobot dari distribusi normal multivariat.
- Matriks tanggung jawab (responsibility) menunjukkan seberapa kuat setiap komponen menjelaskan tiap sampel.
- Parameter diperkirakan menggunakan algoritma EM; bentuk kovarians dapat dipilih dari
full,tied,diag, atauspherical. - Pemilihan model biasanya menggabungkan BIC/AIC dengan beberapa inisialisasi acak agar hasil stabil.
Intuisi #
Metode ini dipahami lewat asumsi dasarnya, karakteristik data, dan dampak pengaturan parameter terhadap generalisasi.
Penjelasan Rinci #
Rumusan #
Kerapatan \(\mathbf{x}\) dinyatakan sebagai
$$ p(\mathbf{x}) = \sum_{k=1}^{K} \pi_k \, \mathcal{N}(\mathbf{x} \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k), $$dengan bobot campuran \(\pi_k\) (tidak negatif dan berjumlah 1). Algoritma EM melakukan:
- E-step: menghitung tanggung jawab \(\gamma_{ik}\). $$ \gamma_{ik} = \frac{\pi_k \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)} {\sum_{j=1}^K \pi_j \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)}. $$
- M-step: memperbarui \(\pi_k, \boldsymbol{\mu}_k, \boldsymbol{\Sigma}k\) menggunakan \(\gamma{ik}\) sebagai bobot.
Log-likelihood meningkat monoton hingga mencapai optimum lokal.
Contoh Python #
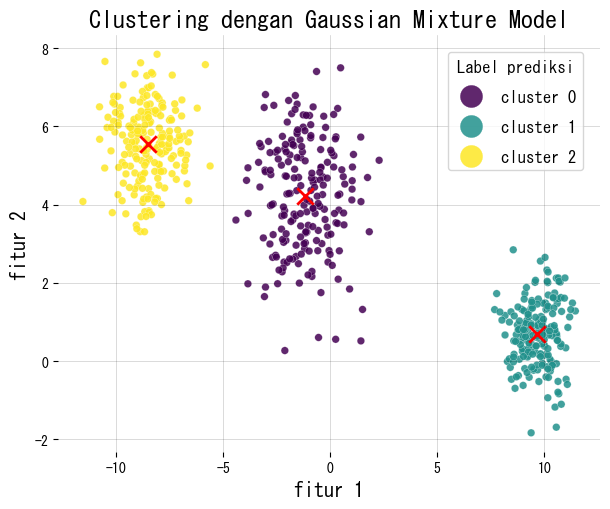
Kita akan menyesuaikan GMM pada data sintetis 2D, menggambar penugasan keras, serta melaporkan bobot campuran dan ukuran matriks tanggung jawab.
| |
Referensi #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society, Series B.
- scikit-learn developers. (2024). Gaussian Mixture Models. https://scikit-learn.org/stable/modules/mixture.html