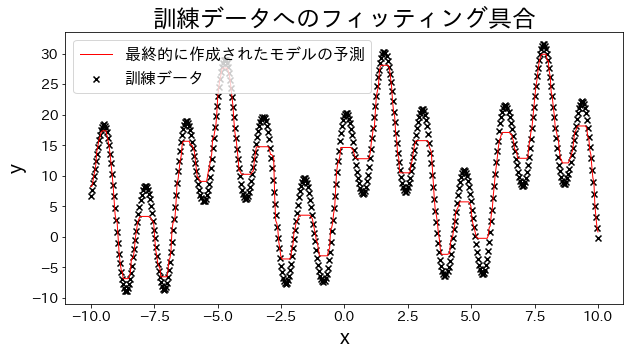
Pada regresi, AdaBoost memaksa iterasi berikutnya untuk fokus pada area prediksi yang masih buruk. Fokus bertahap pada sampel ber-error tinggi membuat ensemble mampu menangkap pola residual nonlinier dengan lebih baik.
# NOTE: Model yang dibuat untuk memeriksa sample_weight modelclassDummyRegressor:def__init__(self):self.model=DecisionTreeRegressor(max_depth=5)self.error_vector=Noneself.X_for_plot=Noneself.y_for_plot=Nonedeffit(self,X,y):self.model.fit(X,y)y_pred=self.model.predict(X)# Bobot dihitung berdasarkan kesalahan regresi# https://github.com/scikit-learn/scikit-learn/blob/main/sklearn/ensemble/_weight_boosting.py#L1130self.error_vector=np.abs(y_pred-y)self.X_for_plot=X.copy()self.y_for_plot=y.copy()returnself.modeldefpredict(self,X,check_input=True):returnself.model.predict(X)defget_params(self,deep=False):return{}defset_params(self,deep=False):return{}
# Data pelatihanX=np.linspace(-10,10,500)[:,np.newaxis]y=(np.sin(X).ravel()+np.cos(4*X).ravel())*10+10+np.linspace(-2,2,500)## Membuat model regresireg=AdaBoostRegressor(DummyRegressor(),n_estimators=100,random_state=100,loss="linear",learning_rate=0.8,)reg.fit(X,y)y_pred=reg.predict(X)# Memeriksa kecocokan model pada data pelatihanplt.figure(figsize=(10,5))plt.scatter(X,y,c="k",marker="x",label="Data pelatihan")plt.plot(X,y_pred,c="r",label="Prediksi model akhir",linewidth=1)plt.xlabel("x")plt.ylabel("y")plt.title("Kecocokan pada Data Pelatihan")plt.legend()plt.show()
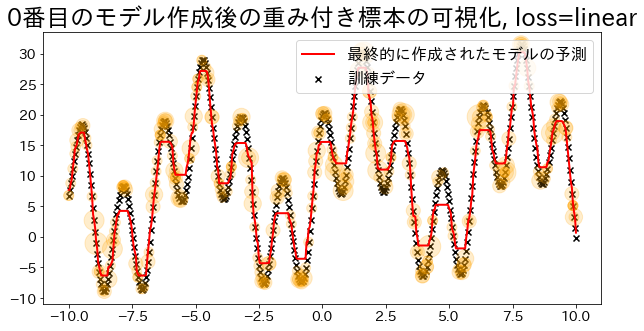
Memvisualisasikan Bobot Sampel (ketika loss='linear')
#
Dalam Adaboost, bobot ditentukan berdasarkan kesalahan regresi. Di bawah pengaturan loss='linear', kita akan memvisualisasikan besarnya bobot. Data dengan bobot yang lebih besar memiliki kemungkinan lebih tinggi untuk dipilih selama pelatihan.
loss{‘linear’, ‘square’, ‘exponential’}, default=’linear’
The loss function to use when updating the weights after each boosting iteration.
defvisualize_weight(reg,X,y,y_pred):"""Fungsi untuk memplot nilai yang sesuai dengan bobot sampel (jumlah kemunculan data yang disampling)
Parameters
----------
reg : sklearn.ensemble._weight_boosting
Model boosting
X : numpy.ndarray
Data pelatihan
y : numpy.ndarray
Data target
y_pred:
Prediksi model
"""assertreg.estimators_isnotNone,"len(reg.estimators_) > 0"fori,estimators_iinenumerate(reg.estimators_):ifi%100==0:# Hitung jumlah kemunculan data yang digunakan dalam pembuatan model ke-iweight_dict={xi:0forxiinX.ravel()}forxiinestimators_i.X_for_plot.ravel():weight_dict[xi]+=1# Plot jumlah kemunculan dengan lingkaran oranye (semakin besar lingkaran, semakin sering muncul)weight_x_sorted=sorted(weight_dict.items(),key=lambdax:x[0])weight_vec=np.array([s*100forxi,sinweight_x_sorted])# Plot grafikplt.figure(figsize=(10,5))plt.title(f"Visualisasi Sampel Berbobot Setelah Model ke-{i}, loss={reg.loss}")plt.scatter(X,y,c="k",marker="x",label="Data Pelatihan")plt.scatter(estimators_i.X_for_plot,estimators_i.y_for_plot,marker="o",alpha=0.2,c="orange",s=weight_vec,)plt.plot(X,y_pred,c="r",label="Prediksi Model Akhir",linewidth=2)plt.legend(loc="upper right")plt.show()## Membuat model regresi dengan loss="linear"reg=AdaBoostRegressor(DummyRegressor(),n_estimators=101,random_state=100,loss="linear",learning_rate=1,)reg.fit(X,y)y_pred=reg.predict(X)visualize_weight(reg,X,y,y_pred)
1
2
3
4
5
6
7
8
9
10
11
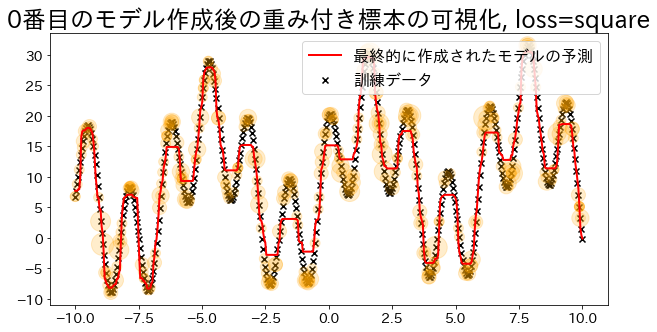
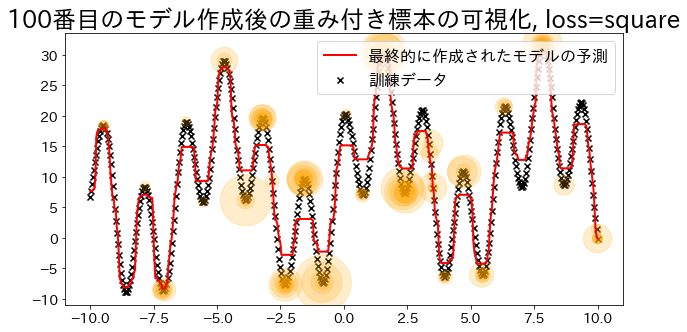
## Membuat Model Regresi dengan `loss="square"`reg=AdaBoostRegressor(DummyRegressor(),n_estimators=101,random_state=100,loss="square",learning_rate=1,)reg.fit(X,y)y_pred=reg.predict(X)visualize_weight(reg,X,y,y_pred)