2.1.6
Regresi Linear Bayesian
Ringkasan
- Regresi linear Bayesian memperlakukan koefisien sebagai variabel acak sehingga dapat memperkirakan prediksi beserta ketidakpastiannya.
- Distribusi posterior diperoleh secara analitik dari prior dan likelihood sehingga tetap andal pada data yang sedikit atau bising.
- Distribusi prediktif berbentuk Gaussian, sehingga mean dan variansinya mudah divisualisasikan untuk mendukung pengambilan keputusan.
BayesianRidgedi scikit-learn menyesuaikan varians noise secara otomatis sehingga implementasi praktis menjadi sederhana.
Intuisi #
Metode ini dipahami lewat asumsi dasarnya, karakteristik data, dan dampak pengaturan parameter terhadap generalisasi.
Penjelasan Rinci #
Formulasi matematis #
Misalkan vektor koefisien \(\boldsymbol\beta\) memiliki prior Gaussian multivariat dengan mean 0 dan varians \(\tau^{-1}\), serta noise observasi \(\epsilon_i \sim \mathcal{N}(0, \alpha^{-1})\). Distribusi posteriornya adalah
$$ p(\boldsymbol\beta \mid \mathbf{X}, \mathbf{y}) = \mathcal{N}(\boldsymbol\beta \mid \boldsymbol\mu, \mathbf{\Sigma}) $$dengan
$$ \mathbf{\Sigma} = (\alpha \mathbf{X}^\top \mathbf{X} + \tau \mathbf{I})^{-1}, \qquad \boldsymbol\mu = \alpha \mathbf{\Sigma} \mathbf{X}^\top \mathbf{y}. $$Distribusi prediktif untuk masukan baru \(\mathbf{x}*\) juga Gaussian, \(\mathcal{N}(\hat{y}, \sigma_^2)\). BayesianRidge mengestimasi \(\alpha\) dan \(\tau\) langsung dari data sehingga tidak perlu disetel manual.
Eksperimen dengan Python #
Contoh berikut membandingkan mínimos kuadrat biasa dan regresi linear Bayesian pada data yang mengandung outlier.
| |
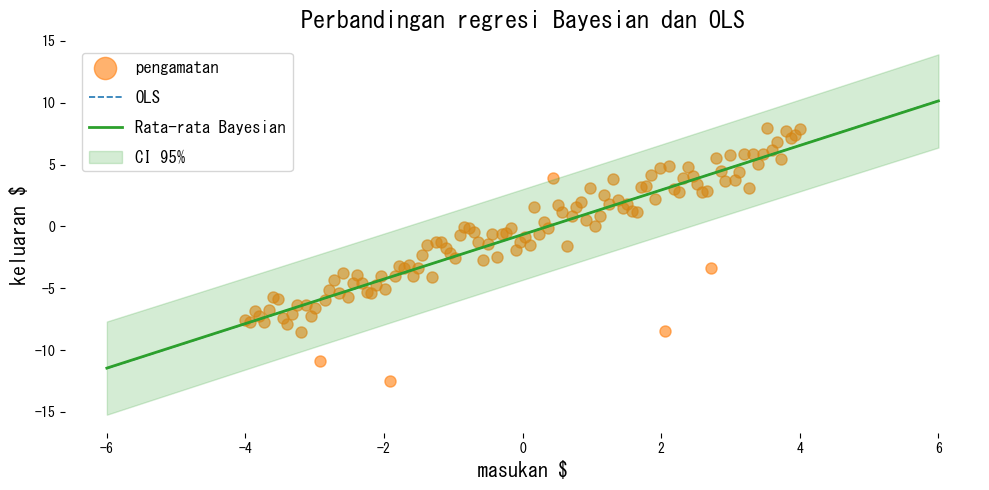
Cara membaca hasil #
- OLS mudah terpengaruh oleh outlier, sedangkan regresi Bayesian menjaga prediksi rata-rata tetap stabil.
return_std=Truememberikan simpangan baku prediktif sehingga interval kredibel dapat digambar dengan mudah.- Memeriksa varians posterior membantu mengidentifikasi koefisien mana yang masih memiliki ketidakpastian besar.
Referensi #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press.