2.1.1
Regresi linear
Ringkasan
- Regresi linear memodelkan hubungan linier antara masukan dan keluaran dan menjadi landasan untuk prediksi maupun interpretasi.
- Metode kuadrat terkecil (ordinary least squares) menghitung koefisien dengan meminimalkan jumlah kuadrat residu sehingga menghasilkan solusi tertutup.
- Koefisien kemiringan menunjukkan seberapa besar keluaran berubah ketika masukan bertambah satu satuan, sedangkan intercept memberi nilai harapan saat masukan bernilai nol.
- Jika noise atau pencilan besar, kombinasikan standardisasi dan pendekatan robust agar praproses dan evaluasi tetap andal.
Intuisi #
Metode ini dipahami lewat asumsi dasarnya, karakteristik data, dan dampak pengaturan parameter terhadap generalisasi.
Penjelasan Rinci #
Formulasi matematis #
Model linear satu variabel ditulis sebagai
$$ y = w x + b. $$Dengan meminimalkan jumlah kuadrat residu \(\epsilon_i = y_i - (w x_i + b)\)
$$ L(w, b) = \sum_{i=1}^{n} \big(y_i - (w x_i + b)\big)^2, $$kita memperoleh solusi analitik
$$ w = \frac{\sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^{n} (x_i - \bar{x})^2}, \qquad b = \bar{y} - w \bar{x}, $$dengan \(\bar{x}\) dan \(\bar{y}\) adalah rata-rata \(x\) dan \(y\). Ide yang sama berlaku untuk regresi multivariat menggunakan vektor dan matriks.
Eksperimen dengan Python #
Contoh berikut menyesuaikan garis regresi menggunakan scikit-learn dan menampilkan hasilnya. Kodenya sama seperti versi bahasa Jepang sehingga gambar yang dihasilkan konsisten.
| |
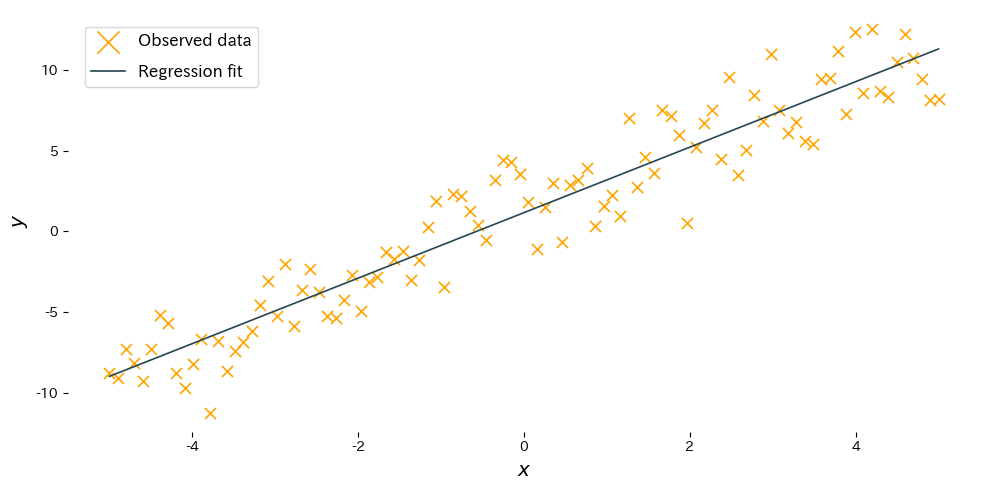
Membaca hasil #
- Kemiringan \(w\): menunjukkan seberapa besar keluaran naik atau turun ketika masukan bertambah satu satuan; estimasinya seharusnya mendekati nilai sebenarnya.
- Intercept \(b\): memberikan nilai harapan saat masukan bernilai 0 dan menggeser garis secara vertikal.
- Menstandardisasi fitur dengan
StandardScalermembantu stabilitas ketika skala masukan berbeda-beda.
Referensi #
- Draper, N. R., & Smith, H. (1998). Applied Regression Analysis (3rd ed.). John Wiley & Sons.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.