2.1.4
Regresi polinomial
Ringkasan
- Regresi polinomial menambahkan fitur berupa pangkat sehingga model linear dapat menyesuaikan hubungan nonlinier.
- Model tetap berbentuk kombinasi linear dari koefisien, sehingga solusi tertutup dan interpretabilitas tetap terjaga.
- Semakin tinggi derajat polinomial semakin ekspresif, tetapi risiko overfitting juga meningkat; regularisasi dan validasi silang menjadi penting.
- Standardisasi fitur dan penyetelan derajat beserta kekuatan penalti memberi prediksi yang stabil.
Intuisi #
Metode ini dipahami lewat asumsi dasarnya, karakteristik data, dan dampak pengaturan parameter terhadap generalisasi.
Penjelasan Rinci #
Formulasi matematis #
Untuk \(\mathbf{x} = (x_1, \dots, x_m)\) kita bentuk vektor fitur polinomial \(\phi(\mathbf{x})\) hingga derajat \(d\). Contohnya, jika \(m = 2\) dan \(d = 2\),
$$ \phi(\mathbf{x}) = (1, x_1, x_2, x_1^2, x_1 x_2, x_2^2), $$sehingga modelnya
$$ y = \mathbf{w}^\top \phi(\mathbf{x}). $$Jumlah istilah akan cepat bertambah saat derajat meningkat, karenanya dalam praktik biasanya mulai dari derajat 2 atau 3 dan dipadukan dengan regularisasi (misalnya Ridge).
Eksperimen dengan Python #
Contoh berikut menambahkan fitur hingga derajat tiga dan menyesuaikan kurva pada data yang berasal dari fungsi kubik ditambah noise.
| |
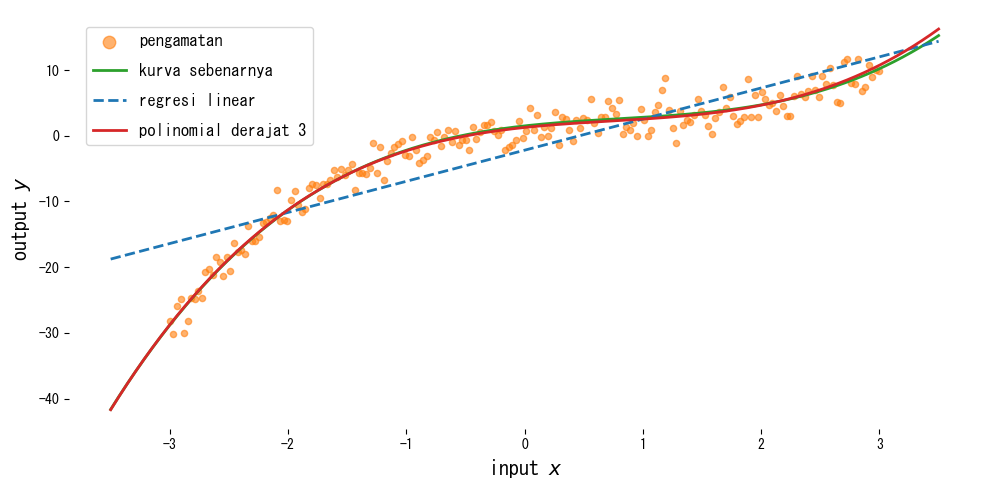
Membaca hasil #
- Regresi linear biasa gagal mengikuti kelengkungan (terutama di tengah), sedangkan model kubik mengikuti kurva sebenarnya dengan baik.
- Derajat yang lebih tinggi meningkatkan kecocokan pada data latih, tetapi dapat membuat prediksi di luar rentang menjadi tidak stabil.
- Menggabungkan fitur polinomial dengan regresi ter-regularisasi (misalnya Ridge) di dalam pipeline membantu menekan overfitting.
Referensi #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.