2.1.11
Weighted Least Squares (WLS)
Ringkasan
- WLS memberikan bobot khusus pada tiap observasi sehingga pengukuran yang lebih dapat dipercaya memiliki pengaruh lebih besar pada garis regresi.
- Mengalikan error kuadrat dengan bobot membuat observasi ber-varians tinggi kurang berpengaruh dan menjaga estimasi tetap dekat dengan data yang andal.
- WLS dapat dijalankan menggunakan
LinearRegressiondi scikit-learn dengan menyediakansample_weight. - Bobot dapat berasal dari varians yang diketahui, analisis residual, atau pengetahuan domain; perancangannya sangat krusial.
Intuisi #
Metode ini dipahami lewat asumsi dasarnya, karakteristik data, dan dampak pengaturan parameter terhadap generalisasi.
Penjelasan Rinci #
Formulasi matematis #
Dengan bobot positif \(w_i\) kita meminimalkan
$$ L(\boldsymbol\beta, b) = \sum_{i=1}^{n} w_i \left(y_i - (\boldsymbol\beta^\top \mathbf{x}_i + b)\right)^2. $$Pilihan idealnya adalah \(w_i \propto 1/\sigma_i^2\) (kebalikan varians) sehingga observasi yang presisi memiliki pengaruh lebih besar.
Eksperimen dengan Python #
Kami membandingkan OLS dan WLS pada data dengan tingkat noise berbeda di setiap wilayah.
| |
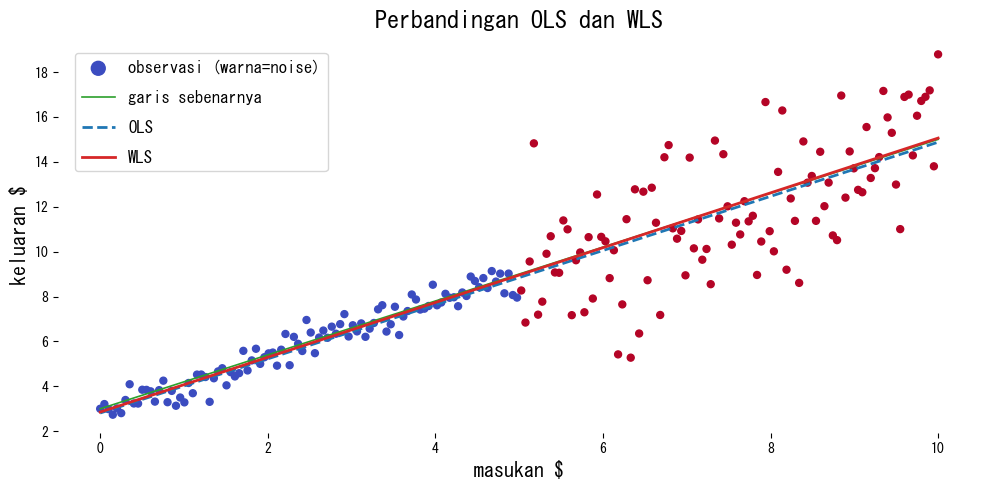
Cara membaca hasil #
- Pemberian bobot menarik garis hasil fitting ke wilayah dengan noise rendah sehingga mendekati garis sebenarnya.
- OLS terdistorsi oleh wilayah dengan noise tinggi dan cenderung meremehkan kemiringan.
- Kinerja sangat bergantung pada pemilihan bobot yang tepat; diagnosa dan intuisi domain sangat membantu.
Referensi #
- Carroll, R. J., & Ruppert, D. (1988). Transformation and Weighting in Regression. Chapman & Hall.
- Seber, G. A. F., & Lee, A. J. (2012). Linear Regression Analysis (2nd ed.). Wiley.