2.3.1
Pohon keputusan (klasifikasi)
- Pohon keputusan untuk klasifikasi membagi ruang fitur dengan serangkaian pertanyaan if-then sehingga setiap daun berisi hampir satu kelas saja.
- Kualitas pemisahan dinilai memakai ukuran impuritas seperti indeks Gini atau entropi; pilih yang paling sesuai dengan biaya salah klasifikasi pada kasus Anda.
- Membatasi kedalaman, jumlah sampel minimum per node, atau melakukan pruning mencegah pohon menghafal derau sekaligus menjaga interpretabilitas.
- Menampilkan wilayah keputusan dan diagram pohon memudahkan komunikasi hasil kepada pemangku kepentingan.
Intuisi #
Metode ini dipahami lewat asumsi dasarnya, karakteristik data, dan dampak pengaturan parameter terhadap generalisasi.
Penjelasan Rinci #
1. Gambaran umum #
Pohon keputusan adalah model supervised yang memecah ruang input secara rekursif. Setiap node internal menanyakan sesuatu seperti “apakah (x_j \le s)?”. Untuk tugas klasifikasi kita menginginkan daun yang sangat murni, artinya labelnya hampir seragam. Hasil akhirnya adalah kumpulan aturan ringkas yang mudah diubah menjadi logika bisnis.
2. Ukuran impuritas #
Misalkan (t) sebuah node dan (p_k) proporsi kelas (k) di dalamnya. Dua ukuran impuritas yang umum ialah
$$ \mathrm{Gini}(t) = 1 - \sum_k p_k^2, $$$$ H(t) = - \sum_k p_k \log p_k. $$Jika node (t) dibagi menggunakan fitur (x_j) dengan ambang (s), kita hitung keuntungan
$$ \Delta I = I(t) - \frac{n_L}{n_t} I(t_L) - \frac{n_R}{n_t} I(t_R), $$dengan (I(\cdot)) adalah Gini atau entropi, (t_L) dan (t_R) node anak, serta (n_t) jumlah sampel yang mencapai (t). Split terbaik adalah yang memaksimalkan (\Delta I).
3. Contoh Python #
Cuplikan berikut membuat data sintetis dua kelas lewat make_classification, melatih DecisionTreeClassifier, dan menggambar wilayah keputusannya. Mengganti criterion="gini" menjadi "entropy" mengubah ukuran impuritas yang dipakai.
| |
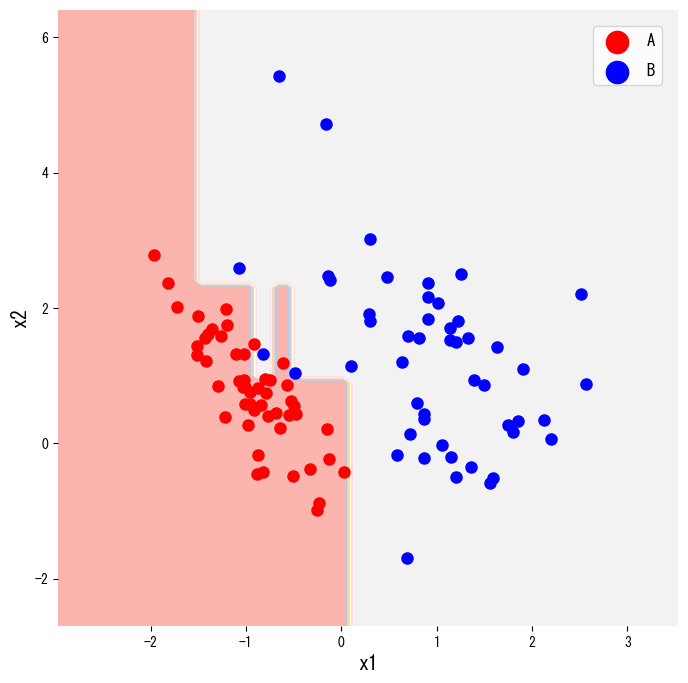
plot_tree menampilkan struktur lengkap pohon sehingga mudah dibaca di laporan atau presentasi.
| |

4. Referensi #
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth.
- scikit-learn developers. (2024). Decision Trees. https://scikit-learn.org/stable/modules/tree.html