2.3.2
Pohon keputusan (regresi)
- Pohon regresi menangkap hubungan nonlinier dengan memecah ruang fitur secara rekursif hingga setiap daun dapat diringkas dengan satu nilai konstan.
- Kualitas split diukur lewat penurunan mean squared error (MSE) pada node anak; semakin besar penurunan, semakin baik pertanyaannya.
- Parameter
max_depth,min_samples_leaf, danccp_alphamembantu menjaga keseimbangan antara ketelitian dan interpretabilitas serta menekan overfitting. - Scatter plot, peta kontur, dan visualisasi pohon memudahkan kita menjelaskan area mana yang berbagi prediksi sama.
Intuisi #
Metode ini dipahami lewat asumsi dasarnya, karakteristik data, dan dampak pengaturan parameter terhadap generalisasi.
Penjelasan Rinci #
1. Gambaran umum #
Serupa dengan klasifikasi, pohon regresi menanyakan pertanyaan sederhana tentang fitur, namun targetnya kini bersifat kontinu. Setiap daun mengeluarkan rata-rata sampel yang masuk, sehingga fungsi yang dihasilkan bersifat konstan per segmen. Pohon yang dalam menangkap detail halus, sedangkan pohon dangkal menjaga tren global.
2. Kriteria pemisahan (reduksi varians) #
Untuk node (t) dengan (n_t) sampel dan rata-rata (\bar{y}_t), impuritasnya didefinisikan sebagai
$$ \mathrm{MSE}(t) = \frac{1}{n_t} \sum_{i \in t} (y_i - \bar{y}_t)^2. $$Jika (t) dibagi menggunakan fitur (x_j) dan ambang (s), keuntungan yang diperoleh adalah
$$ \Delta = \mathrm{MSE}(t) - \frac{n_L}{n_t} \mathrm{MSE}(t_L) - \frac{n_R}{n_t} \mathrm{MSE}(t_R). $$Split terbaik adalah yang memaksimalkan (\Delta); ketika tidak ada split yang memberikan keuntungan positif, node berubah menjadi daun.
3. Contoh Python #
Cuplikan pertama melatih pohon dangkal pada sampel sinusoid yang diberi derau untuk menunjukkan bentuk fungsi yang konstan per segmen. Eksperimen kedua menggunakan dua fitur, menghitung (R^2), RMSE, MAE, dan menggambarkan permukaan prediksi serta struktur pohonnya.
| |
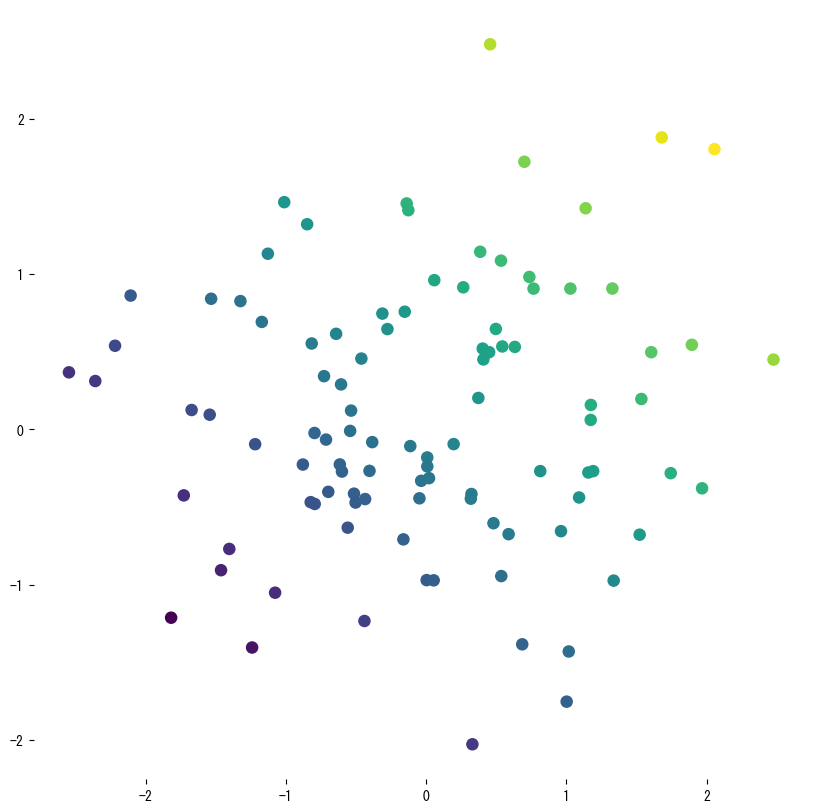
| |
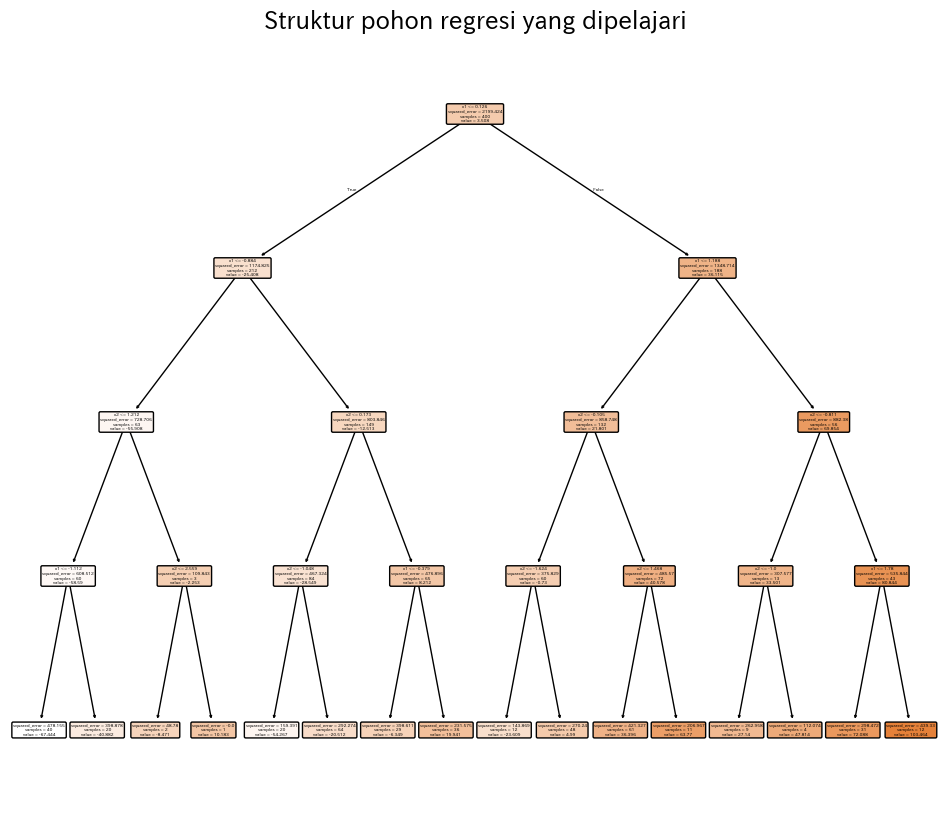
| |

4. Referensi #
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth.
- scikit-learn developers. (2024). Decision Trees. https://scikit-learn.org/stable/modules/tree.html