4.1.2
Validasi silang stratifikasi
Ringkasan
- Stratified k-fold menjaga proporsi kelas pada setiap fold, sangat penting untuk data yang tidak seimbang.
- Bandingkan k-fold stratifikasi dengan k-fold standar untuk melihat perbedaan bias kelas.
- Catat kiat desain ketika ketidakseimbangan sangat ekstrem dan bagaimana membaca hasilnya di lapangan.
| |
Membangun model dan menjalankan validasi silang #
Dataset percobaan #
| |
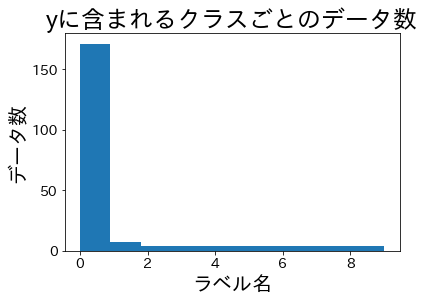
Rasio kelas setelah split #
Kita bagi data, kemudian periksa proporsi kelas pada set pelatihan dan validasi.
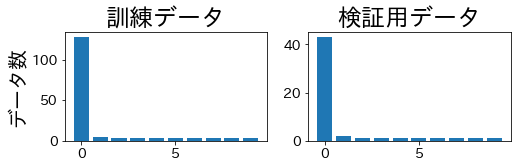
StratifiedKFold #
Proporsi kelas tetap seragam di pelatihan maupun validasi.
| |
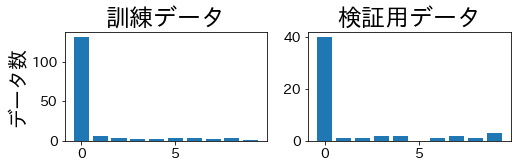
KFold biasa #
K-fold standar bisa menghasilkan fold validasi yang sama sekali tidak memuat kelas minoritas tertentu.
| |
Pertimbangan praktis #
- Ketidakseimbangan ekstrem: jika kelas minoritas hanya memiliki sedikit sampel, kombinasikan stratifikasi dengan validasi silang berulang untuk mengurangi variansi.
- Tugas regresi: discretise target menjadi bin agar
StratifiedKFolddapat menjaga distribusi nilai. - Kebijakan pengacakan: aktifkan
shuffle=True(dengan seed tetap) bila dataset memiliki urutan temporal atau kelompok yang bisa menimbulkan bias.
Stratified k-fold adalah pengganti langsung k-fold ketika keseimbangan kelas menjadi isu utama. Ia menghasilkan split validasi yang lebih adil, menstabilkan metrik seperti ROC-AUC, dan memperbaiki perbandingan antar model pada dataset tidak seimbang.