3.3.5
Memberi label anomali dengan Isolation Forest
<p><b>Isolation Forest</b> merupakan algoritma deteksi anomali tanpa label yang bekerja dengan memisahkan titik data menggunakan pohon binari acak. Sampel yang cepat “terisolasi” (butuh sedikit pemisahan) dianggap sebagai outlier.</p>
Menyusun data contoh
#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
rng = np.random.default_rng(42)
X, _ = make_moons(n_samples=1_000, noise=0.08, random_state=42)
anomaly_index = np.arange(0, 1_000, 60)
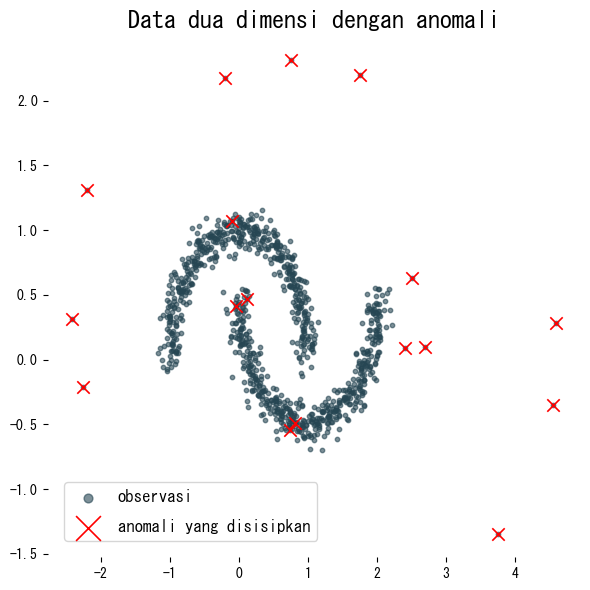
X[anomaly_index] *= 2.5 # memperbesar sebagian titik agar menjadi outlier
plt.figure(figsize=(6, 6))
plt.scatter(X[:, 0], X[:, 1], s=10, alpha=0.6, label="observasi")
plt.scatter(X[anomaly_index, 0], X[anomaly_index, 1], marker="x", s=80, c="red", label="anomali yang disisipkan")
plt.legend()
plt.title("Data dua dimensi dengan anomali")
plt.tight_layout()
plt.show()
|
Melatih Isolation Forest
#
1
2
3
4
5
6
7
8
9
10
11
12
13
| from sklearn.ensemble import IsolationForest
detector = IsolationForest(
n_estimators=200,
max_samples=256,
contamination=0.02,
random_state=42,
)
detector.fit(X)
scores = detector.decision_function(X)
pred = detector.predict(X) # -1 berarti outlier
detected_index = np.where(pred < 0)[0]
|
Parameter contamination mengontrol perkiraan proporsi outlier di dataset. Jika tidak yakin, mulai dari nilai kecil lalu tingkatkan secara bertahap.
Memvisualisasikan hasilnya
#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| plt.figure(figsize=(6, 6))
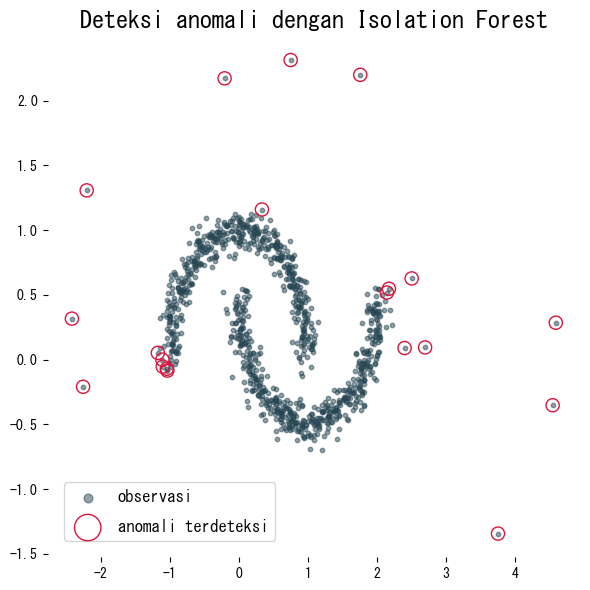
plt.scatter(X[:, 0], X[:, 1], s=10, alpha=0.5, label="observasi")
plt.scatter(
X[detected_index, 0],
X[detected_index, 1],
facecolor="none",
edgecolor="crimson",
s=90,
label="anomali terdeteksi",
)
plt.title("Deteksi anomali dengan Isolation Forest")
plt.legend()
plt.tight_layout()
plt.show()
|
Tips praktis
#
- Jangan membuat
contamination terlalu besar—nilai tinggi akan menyebabkan banyak false positive. Untuk log produksi, nilai 0.01 atau lebih kecil biasanya aman. max_samples menentukan ukuran subsample setiap pohon. Jika dataset sangat besar, gunakan nilai tetap (misalnya 512) agar pelatihan tetap cepat.- Gunakan
decision_function bila Anda perlu mengurutkan anomali berdasarkan skor. Threshold dapat disesuaikan belakangan tanpa melatih ulang model. - Kombinasikan dengan scaler (StandardScaler atau RobustScaler) jika tiap fitur memiliki skala yang sangat berbeda.