LDA
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn.datasets import make_blobs
実験用のデータ
X, y = make_blobs(
n_samples=600, n_features=3, random_state=11711, cluster_std=4, centers=3
)
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(projection="3d")
ax.scatter(X[:, 0], X[:, 1], X[:, 2], marker="o", c=y)
ax.set_xlabel("$x_1$")
ax.set_ylabel("$x_2$")
ax.set_zlabel("$x_3$")

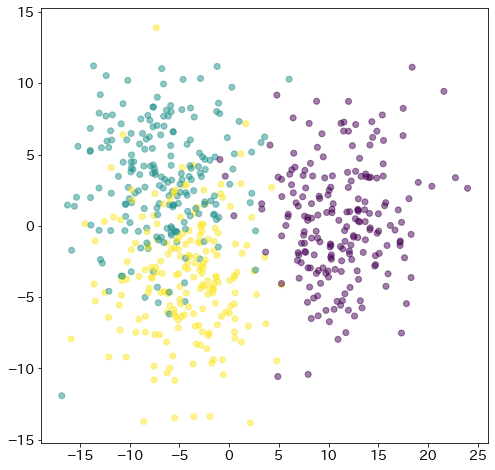
LDAで二次元に次元削減する
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
lda = LDA(n_components=2).fit(X, y)
X_lda = lda.transform(X)
fig = plt.figure(figsize=(8, 8))
plt.scatter(X_lda[:, 0], X_lda[:, 1], c=y, alpha=0.5)
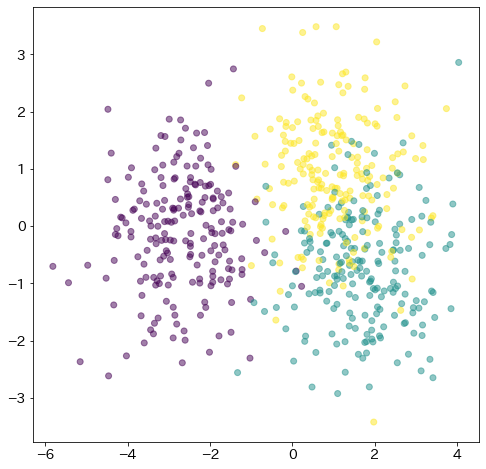
PCAとLDAの比較
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
fig = plt.figure(figsize=(8, 8))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, alpha=0.5)