最小二乗法
最小二乗法とは、数値のペア $(x_i, y_i)$ の集まりに対してその関係性を知るためにある関数をフィットさせたい時、 残差の二乗和を最小にするように関数の係数を求めることを指しています。このページでは、サンプルデータに対してscikit-learnを用いて最小二乗法を実行してみます。
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
japanize_matplotlib はグラフに日本語を表示するためにインポートしています。
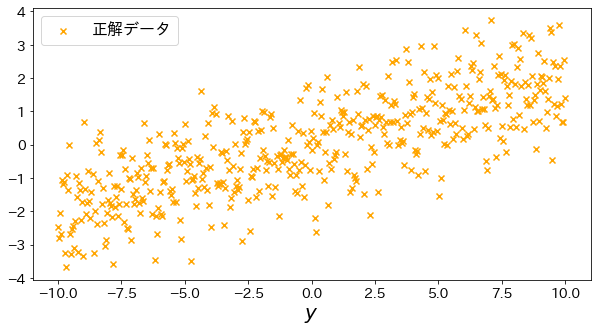
実験用の回帰データを作成
np.linspace を使ってデータを作成します。これは、指定した値の間を等間隔に区切った値のリストを作成します。
以下のコードでは線形回帰をするためのサンプルデータを500個作成しています。
# 訓練データ
n_samples = 500
X = np.linspace(-10, 10, n_samples)[:, np.newaxis]
epsolon = np.random.normal(size=n_samples)
y = np.linspace(-2, 2, n_samples) + epsolon
# 直線を可視化
plt.figure(figsize=(10, 5))
plt.scatter(X, y, marker="x", label="正解データ", c="orange")
plt.xlabel("$x_1$")
plt.xlabel("$y$")
plt.legend()
plt.show()
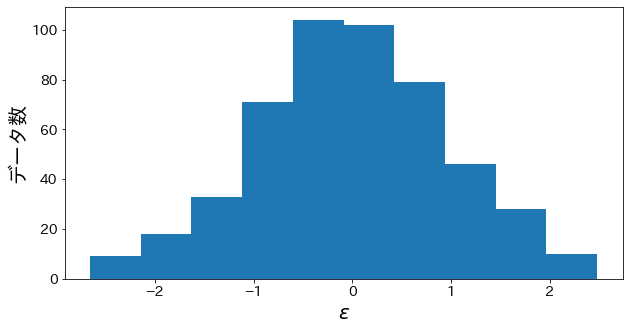
yに乗っているノイズの確認
y = np.linspace(-2, 2, n_samples) + epsolon の epsolon のヒストグラムをプロットします。
正規分布に近い分布のノイズが目的変数に乗っていることを確認します。
plt.figure(figsize=(10, 5))
plt.hist(epsolon)
plt.xlabel("$\epsilon$")
plt.ylabel("データ数")
plt.show()
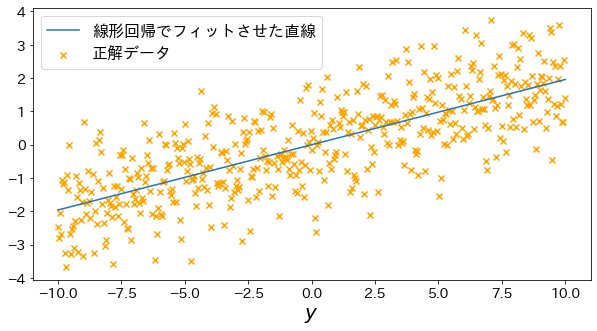
最小二乗法で直線を当てはめる
# モデルをフィット
lin_r = make_pipeline(StandardScaler(with_mean=False), LinearRegression()).fit(X, y)
y_pred = lin_r.predict(X)
# 直線を可視化
plt.figure(figsize=(10, 5))
plt.scatter(X, y, marker="x", label="正解データ", c="orange")
plt.plot(X, y_pred, label="線形回帰でフィットさせた直線")
plt.xlabel("$x_1$")
plt.xlabel("$y$")
plt.legend()
plt.show()