企業の財務情報をパース
pythonで複数の会社の財務データを比較します。 ここでは、近い業界にある3つの会社の期ごとの売上と当期純利益の推移を見てみようと思います。
このページの日英訳は以下のサイトのものを参考しつつ作成していますが、正確性に欠ける可能性があるのであくまで参考程度にお願い致します。 TOMAコンサルタンツグループ株式会社 海外決算書の科目 英語→日本語簡易対訳 損益計算書編
import japanize_matplotlib
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import re
import seaborn as sns
from IPython.core.display import display
# 英日辞書
en_US_ja_JP_table = {
"Revenue": "売上",
"Cost of revenue": "収益コスト",
"Gross profit": "粗利益",
"Sales, General and administrative": "販売費及び一般管理費",
"Other operating expenses": "その他営業費用",
"Total operating expenses": "営業費用",
"Operating income": "営業利益",
"Interest Expense": "支払利息",
"Other income (expense)": "Other income (expense)",
"Income before taxes": "Income before taxes",
"Provision for income taxes": "Provision for income taxes",
"Net income from continuing operations": "Net income from continuing operations",
"Net income available to common shareholders": "普通株式に係る当期純利益",
"Net income": "当期純利益",
"Basic": "Basic",
"Diluted": "Diluted",
"EBITDA": "EBITDA",
"Revenue ": "売上",
"Gross Margin %": " 売上総利益率",
"Operating Income ": "営業利益",
"Operating Margin %": "営業利益率",
"Net Income ": "純利益",
"Earnings Per Share USD": "EPS (USD)",
"Dividends USD": "配当 (USD)",
"Payout Ratio % *": "配当性向",
"Shares Mil": "株数 (Mil)",
"Book Value Per Share * USD": "1株あたり純資産",
"Operating Cash Flow ": "営業キャッシュフロー",
"Cap Spending ": "資本的支出",
"Free Cash Flow ": "フリーキャッシュフロー(FCF)",
"Free Cash Flow Per Share * USD": "1株あたりFCF",
"Working Capital ": "運転資本",
"Key Ratios -> Profitability": "",
"Margins % of Sales": "Margins % of Sales",
"COGS": "売上原価",
"Gross Margin": "売上高総利益率",
"SG&A": "販売費及び一般管理費",
"R&D": "研究開発費",
"Operating Margin": "営業利益率",
"Net Int Inc & Other": "資金運用利益+その他",
"EBT Margin": "EBTマージン",
"Debt/Equity": "負債比率",
"Receivables Turnover": "売上債権回転率",
"Inventory Turnover": "棚卸資産回転率",
"Fixed Assets Turnover": "固定資産回転率",
"Asset Turnover": "総資産回転率",
"USD Mil": "(USD Mil)",
"-Year Average": "年平均",
}
def get_preprocessed_df(
filepath,
is_transpose=True,
drop_ttm_lastqrt=True,
ttm_datetime="2021-12",
lastqtr_datetime="2021-12",
add_ticker_column=True,
):
"""Morningstar, Incのデータを整形する
Args:
filepath (str): ファイルパス
is_transpose (bool, optional): タイムスタンプ列を縦にするかどうか. Defaults to True.
drop_ttm_lastqrt (bool, optional): TTM/Last Qrtの記録は削除する. Defaults to True.
ttm_datetime (str, optional): 「TTM」をどの日付に置き換えるか. Defaults to "2021-12".
lastqtr_datetime (str, optional): 「Latest Qtr」をどの日付に置き換えるか. Defaults to "2021-12".
add_ticker_column (bool, optional): ticker symbolを示した列を追加するか. Defaults to True.
Returns:
DataFrame: 整形済みデータフレーム
"""
df_preprocessed = []
df_header = []
row_header = ""
df = pd.read_table(filepath, header=None)
if not drop_ttm_lastqrt:
print(f"[Note] TTM は {ttm_datetime} 、Last Qtrは {lastqtr_datetime} の日付として扱われます。")
for idx, row in enumerate(df[0]):
# 数値中の「,」を置換する
row = re.sub('"(-?[0-9]+),', '"\\1', row)
row = re.sub(',(-?[0-9]+)",', '\\1",', row)
# 英語を対応する日本語に置き換える
for str_en, str_jp in en_US_ja_JP_table.items():
if str_en in row:
row = row.replace(str_en, str_jp)
# TTMがある行はタイムスタンプなのでヘッダー扱いにする
if "TTM" in row or "Latest Qtr" in row:
if drop_ttm_lastqrt:
row = row.replace("TTM", "###IGNORE###")
row = row.replace("Latest Qtr", "###IGNORE###")
else:
assert ttm_datetime not in row, "その日付はすでに存在しています!"
assert lastqtr_datetime not in row, "その日付はすでに存在しています!"
row = row.replace("TTM", ttm_datetime)
row = row.replace("Latest Qtr", lastqtr_datetime)
df_header = row.split(",")
if is_transpose:
df_header[0] = "月"
else:
df_header = ["月"] + df_header
continue
# 数値に変換できるデータは数値に変換してDataFrameに追加
if len(row_splited := row.split(",")) > 1:
row_data = [
float(v) if re.match(r"^-?\d+(?:\.\d+)$", v) is not None else v
for v in row_splited
]
if is_transpose:
row_data[0] = (
f"{row_header}/{row_data[0]}" if row_header else f"{row_data[0]}"
)
else:
row_data = [row_header] + row_data
df_preprocessed.append(row_data)
else:
# 先頭の行はファイルのタイトルが入っているので無視
row_header = f"{row}" if idx > 0 else ""
# データフレーム作成
df_preprocessed = pd.DataFrame(df_preprocessed)
df_preprocessed.columns = df_header
if drop_ttm_lastqrt:
df_preprocessed.drop("###IGNORE###", axis=1, inplace=True)
# 不要な文字列を削除
df_preprocessed.fillna(np.nan, inplace=True)
if is_transpose:
df_preprocessed = df_preprocessed.T.reset_index()
df_preprocessed.columns = df_preprocessed.iloc[0, :]
df_preprocessed.drop(0, inplace=True)
df_preprocessed["月"] = pd.to_datetime(df_preprocessed["月"])
for colname in df_preprocessed.columns:
if colname != "月":
df_preprocessed[colname] = pd.to_numeric(
df_preprocessed[colname], errors="coerce"
)
if add_ticker_column:
filename = os.path.basename(filepath)
ticker_symbol = filename[: filename.index(" ")]
df_preprocessed["ticker"] = [
ticker_symbol for _ in range(df_preprocessed.shape[0])
]
return df_preprocessed
データを読み込む
以下の例ではMorningstar, Inc社から提供されているデータを一部引用して使用しています。 このサイトで、指定した企業の財務情報をまとめたcsvファイルを取得します。ここの例ではGolden Ocean Group Ltdなどのデータを使用しています。
※あくまで表示例であり正確性は保証しません。万一この情報に基づいて被ったいかなる損害についても一切責任を負い兼ねます。
df_is_gogl = get_preprocessed_df("data/GOGL Income Statement.csv")
df_kr_gogl = get_preprocessed_df("data/GOGL Key Ratios.csv")
df_is_zim = get_preprocessed_df("data/ZIM Income Statement.csv")
df_kr_zim = get_preprocessed_df("data/ZIM Key Ratios.csv")
df_is_sblk = get_preprocessed_df("data/SBLK Income Statement.csv")
df_kr_sblk = get_preprocessed_df("data/SBLK Key Ratios.csv")
df_income_statement = pd.concat([df_is_gogl, df_is_sblk, df_is_zim])
df_key_ratio = pd.concat([df_kr_gogl, df_kr_zim, df_kr_sblk])
display(df_income_statement.head())
display(df_key_ratio.head())
| 月 | 売上 | 収益コスト | 粗利益 | Operating expenses/販売費及び一般管理費 | Operating expenses/その他営業費用 | Operating expenses/営業費用 | Operating expenses/営業利益 | Operating expenses/支払利息 | Operating expenses/Other income (expense) | ... | Operating expenses/当期純利益 from continuing operations | Operating expenses/当期純利益 | Operating expenses/普通株式に係る当期純利益 | Earnings per share/Basic | Earnings per share/Diluted | Weighted average shares outstanding/Basic | Weighted average shares outstanding/Diluted | Weighted average shares outstanding/EBITDA | ticker | Operating expenses/Other | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2016-12-01 | 258 | 313 | -55 | 13 | 2 | 15 | -70 | 42 | -16 | ... | -128 | -128 | -128 | -1.34 | -1.34 | 95 | 95 | -22 | GOGL | NaN |
| 2 | 2017-12-01 | 460 | 400 | 60 | 13 | -4 | 9 | 51 | 57 | 3 | ... | -2 | -2 | -2 | -0.02 | -0.02 | 125 | 125 | 133 | GOGL | NaN |
| 3 | 2018-12-01 | 656 | 499 | 158 | 15 | -3 | 12 | 146 | 73 | 12 | ... | 85 | 85 | 85 | 0.59 | 0.59 | 144 | 144 | 250 | GOGL | NaN |
| 4 | 2019-12-01 | 706 | 590 | 116 | 14 | 1 | 15 | 101 | 57 | -6 | ... | 37 | 37 | 37 | 0.26 | 0.26 | 144 | 144 | 188 | GOGL | NaN |
| 5 | 2020-12-01 | 608 | 564 | 44 | 14 | -3 | 11 | 33 | 45 | -126 | ... | -138 | -138 | -138 | -0.96 | -0.96 | 143 | 143 | 18 | GOGL | NaN |
5 rows × 22 columns
| 月 | Financials/売上 (USD Mil) | Financials/\t売上総利益率 | Financials/営業利益(USD Mil) | Financials/営業利益率 | Financials/純利益(USD Mil) | Financials/EPS (USD) | Financials/配当 (USD) | Financials/配当性向 | Financials/株数 (Mil) | ... | Key Ratios -> Financial Health/負債比率 | Key Ratios -> Efficiency Ratios/Days Sales Outstanding | Key Ratios -> Efficiency Ratios/Days Inventory | Key Ratios -> Efficiency Ratios/Payables Period | Key Ratios -> Efficiency Ratios/Cash Conversion Cycle | Key Ratios -> Efficiency Ratios/売上債権回転率 | Key Ratios -> Efficiency Ratios/棚卸資産回転率 | Key Ratios -> Efficiency Ratios/固定資産回転率 | Key Ratios -> Efficiency Ratios/総資産回転率 | ticker | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2011-12-01 | 95.0 | 68.2 | 38.0 | 40.4 | 33.0 | 6.12 | 9.00 | NaN | 5.0 | ... | 0.42 | 18.79 | 32.12 | 36.01 | 14.89 | 19.43 | 11.36 | 0.21 | 0.18 | GOGL |
| 2 | 2012-12-01 | 37.0 | 38.2 | 10.0 | 26.8 | -53.0 | -10.08 | 5.40 | 488.7 | 5.0 | ... | 0.39 | 48.04 | 39.37 | 26.39 | 61.02 | 7.60 | 9.27 | 0.11 | 0.08 | GOGL |
| 3 | 2013-12-01 | 38.0 | 31.3 | 7.0 | 18.2 | -4.0 | -0.69 | 3.15 | NaN | 6.0 | ... | 0.30 | 26.25 | 20.60 | 19.16 | 27.68 | 13.91 | 17.72 | 0.13 | 0.09 | GOGL |
| 4 | 2014-12-01 | 97.0 | 25.4 | 19.0 | 20.1 | 16.0 | 1.38 | 2.81 | 184.2 | 11.0 | ... | 0.39 | 11.45 | 37.85 | 16.10 | 33.20 | 31.88 | 9.64 | 0.13 | 0.12 | GOGL |
| 5 | 2015-12-01 | 190.0 | -28.6 | -72.0 | -37.6 | -221.0 | -7.30 | NaN | NaN | 30.0 | ... | 0.80 | 11.90 | 21.19 | 5.57 | 27.51 | 30.68 | 17.22 | 0.13 | 0.11 | GOGL |
5 rows × 87 columns
変化を可視化する
seabornを使ってグラフを作成してみます。
def show_barchart(data, x="月", y="売上", hue="ticker", is_log_scale=False):
"""バーチャートを表示する
Args:
data (pandas.DataFrame): データフレーム
x (str, optional): 時間軸. Defaults to "月".
y (str, optional): 比較する指標. Defaults to "売上".
hue (str, optional): 何基準で比較するか. Defaults to "ticker".
is_log_scale (bool, optional): logスケールで表示するかどうか. Defaults to False.
"""
sns.set_theme(style="whitegrid", rc={"figure.figsize": (10, 4)})
japanize_matplotlib.japanize()
g = sns.barplot(data=data, x=x, y=y, hue=hue)
g.set_xticklabels(
[xt.get_text().split("-01")[0] for xt in g.get_xticklabels()]
) # TODO: mdates.DateFormatterで日付を表示するとなぜか日付がずれるのでラベルを直接書き換える
g.tick_params(axis="x", rotation=90)
if is_log_scale:
g.set_yscale("log")
plt.legend(loc="upper left", title="Ticker Name")
plt.title(f"{y}の比較", fontsize=14)
plt.show()
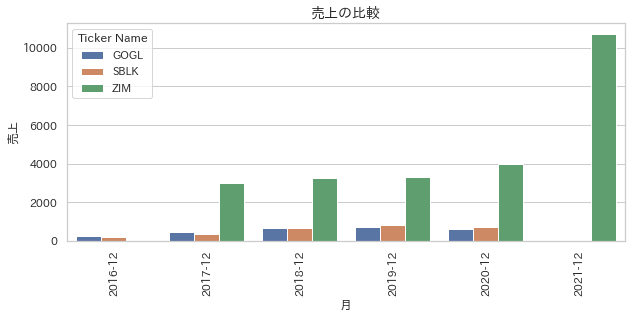
show_barchart(df_income_statement, x="月", y="売上", hue="ticker")
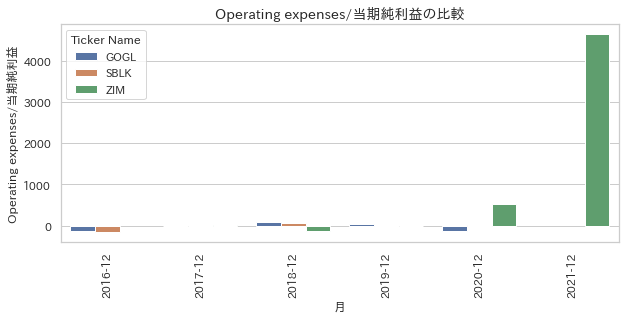
show_barchart(df_income_statement, x="月", y="Operating expenses/当期純利益", hue="ticker")