pdfから表を抽出
camelotを使う場合
必要なライブラリをインストール
今回はCamelotというライブラリを使ってpdfからテーブルを抽出します。
opencv-contrib-python、camelot、tabula-pyが必要なので適宜インストールします。
poetry add opencv-contrib-python camelot tabula-py ghostscript
Ghostscriptというソフトウェアも必要なのでインストールします。 OSによってインストール方法が異なるので注意してください。 インストール方法はこちらを参照してください。
ghostscriptがインストールされているか確認する
from ctypes.util import find_library
find_library("gs") # gsが実行可能ならば /usr/local/lib/libgs.dylibなどの表示がされます
'/usr/local/lib/libgs.dylib'
pdfからテーブルを抽出する
例として総務省のページで公開されている「政策ごとの予算との対応について」のpdfからテーブルを抽出します。テーブルがパースできたことがわかります。
※jupyterbookでエラーが出る場合があるためコメントアウトしています
import camelot
# pdfを読み込んでテーブルを抽出
# pdf_name = "000788423.pdf"
# tables = camelot.read_pdf(pdf_name)
# print("パースできたテーブル数", tables.n)
# 先頭5行のみ表示
# tables[0].df.head()
今度はFLEX LNGという会社の決算情報をパースしてみます。 データはFLEXLNG|Investor Homeで取得したファイルで実行しています。 今後はテーブルのパースに失敗してしましました。
# pdfを読み込んでテーブルを抽出
pdf_name = "flex-lng-earnings-release-q3-2021.pdf"
tables = camelot.read_pdf(pdf_name)
print("パースできたテーブル数", tables.n)
# 先頭5行のみ表示
# tables[0].df.head()
パースできたテーブル数 0
tabula-py を使う場合
poetry add tabula-pyなどとしてtabulaをインストールしてください。
tabulaはバックグラウンドでtabula-java
を使用していますが、Javaのバージョンが古い場合こちらがエラーになる場合があるようです。
参考文献:subprocess.CalledProcessError While extracting table from PDF using tabula-py
from tabula import read_pdf
tables = read_pdf("flex-lng-earnings-release-q3-2021.pdf", pages="all")
data = tables[1]
data.head()
| ASSETS | Unnamed: 0 | Unnamed: 1 | Unnamed: 2 | Unnamed: 3 | |
|---|---|---|---|---|---|
| 0 | Current assets | NaN | NaN | NaN | NaN |
| 1 | Cash and cash equivalents | 4 | 138,116 | 144,151 | 128,878 |
| 2 | Restricted cash | 4 | 47 | 56 | 84 |
| 3 | Inventory | NaN | 5,915 | 4,075 | 3,656 |
| 4 | Other current assets | 5 | 12,503 | 8,886 | 25,061 |
パースしたテーブルを可視化する
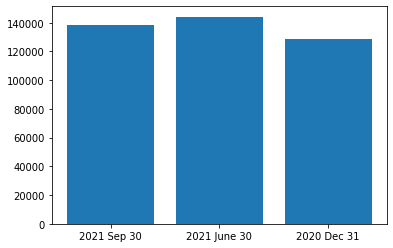
tabulateでパースしたテーブルは文字列になっているので、そこから数値を読み取ります。
import matplotlib.pyplot as plt
d = data.query("ASSETS=='Cash and cash equivalents'").iloc[0][2:]
# パースしたテーブルは文字列になっているので数値に変換する
d = [int(v.replace(",", "")) for v in d]
# プロット
plt.bar([0, 1, 2], d)
plt.xticks([0, 1, 2], ["2021 Sep 30", "2021 June 30", "2020 Dec 31"])
plt.show()