Isolation Forest
isolation Forestを使って異常値を検出してみます。 このページでは時系列データの中にいくつか異常値を混ぜ、それが検出できるかどうか検証します。 また、最後に異常値と判定したルールを可視化します。
import japanize_matplotlib
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.ensemble import IsolationForest
from sklearn.tree import plot_tree
人工データの作成
[11, 49, 149, 240, 300, 310]の日付にて異常値を混ぜておきます。
カテゴリ変数や整数の特徴も含まれるデータです。数値のみプロットしてみます。
rs = np.random.RandomState(365)
dates = pd.date_range("1 1 2016", periods=365, freq="D")
data = {}
data["月"] = [d.strftime("%m") for d in dates]
data["曜日"] = [d.strftime("%A") for d in dates]
data["特徴1"] = [np.sin(d.day / 50) + np.random.rand() for d in dates]
data["特徴2"] = [np.cos(d.day / 50) + np.random.rand() for d in dates]
data["特徴3"] = [3 * np.random.rand() + np.log(d.dayofyear) * 0.03 for d in dates]
data["特徴4"] = [np.random.choice(["☀", "☂", "☁"]) for d in dates]
column_names = list(data.keys())
anomaly_index = [11, 49, 149, 240, 300, 310]
anomaly_dates = [dates[i] for i in anomaly_index]
for i in anomaly_index:
data["特徴1"][i] = 2.5
data["特徴2"][i] = 0.3
data = pd.DataFrame(data, index=dates)
plt.figure(figsize=(10, 4))
sns.lineplot(data=data, palette="tab10", linewidth=2.5)
<Axes: >
data
| 月 | 曜日 | 特徴1 | 特徴2 | 特徴3 | 特徴4 | |
|---|---|---|---|---|---|---|
| 2016-01-01 | 01 | Friday | 0.432678 | 1.645027 | 1.118289 | ☀ |
| 2016-01-02 | 01 | Saturday | 0.099463 | 1.645734 | 0.289383 | ☀ |
| 2016-01-03 | 01 | Sunday | 0.297490 | 1.613958 | 2.499115 | ☀ |
| 2016-01-04 | 01 | Monday | 1.043077 | 1.029947 | 0.484240 | ☀ |
| 2016-01-05 | 01 | Tuesday | 0.184797 | 1.355265 | 2.795718 | ☁ |
| ... | ... | ... | ... | ... | ... | ... |
| 2016-12-26 | 12 | Monday | 0.914207 | 1.580330 | 0.617349 | ☂ |
| 2016-12-27 | 12 | Tuesday | 1.229753 | 1.599599 | 2.605319 | ☀ |
| 2016-12-28 | 12 | Wednesday | 0.936100 | 1.408378 | 2.540507 | ☀ |
| 2016-12-29 | 12 | Thursday | 1.156575 | 1.428601 | 0.831889 | ☀ |
| 2016-12-30 | 12 | Friday | 1.383185 | 1.544629 | 1.416885 | ☁ |
365 rows × 6 columns
カテゴリ変数の変換
「曜日」のような特徴をIsolation Forestで扱うためにダミー変数に変換します。
X = pd.get_dummies(data)
X
| 特徴1 | 特徴2 | 特徴3 | 月_01 | 月_02 | ... | 曜日_Thursday | 曜日_Tuesday | 曜日_Wednesday | 特徴4_☀ | 特徴4_☁ | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2016-01-01 | 0.432678 | 1.645027 | 1.118289 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| 2016-01-02 | 0.099463 | 1.645734 | 0.289383 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| 2016-01-03 | 0.297490 | 1.613958 | 2.499115 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| 2016-01-04 | 1.043077 | 1.029947 | 0.484240 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| 2016-01-05 | 0.184797 | 1.355265 | 2.795718 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2016-12-26 | 0.914207 | 1.580330 | 0.617349 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| 2016-12-27 | 1.229753 | 1.599599 | 2.605319 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| 2016-12-28 | 0.936100 | 1.408378 | 2.540507 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| 2016-12-29 | 1.156575 | 1.428601 | 0.831889 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| 2016-12-30 | 1.383185 | 1.544629 | 1.416885 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
365 rows × 25 columns
Isolation Forestの作成
ilf = IsolationForest(
n_estimators=100,
max_samples="auto",
contamination=0.01,
max_features=5,
bootstrap=False,
random_state=np.random.RandomState(365),
)
ilf.fit(X)
data["is_anomaly"] = ilf.predict(X) < 0
data["anomaly_score"] = ilf.decision_function(X)
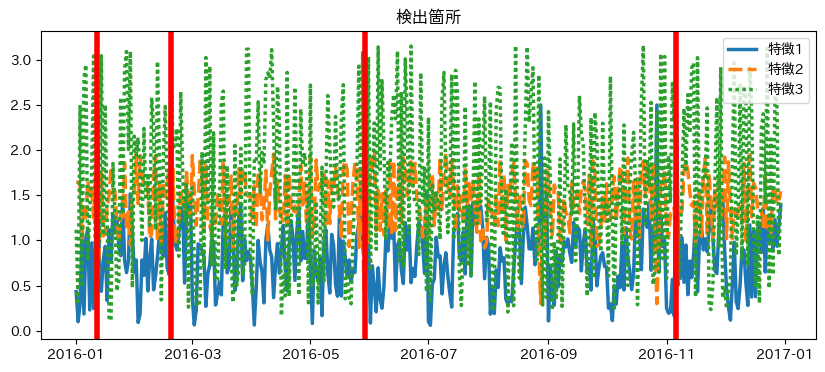
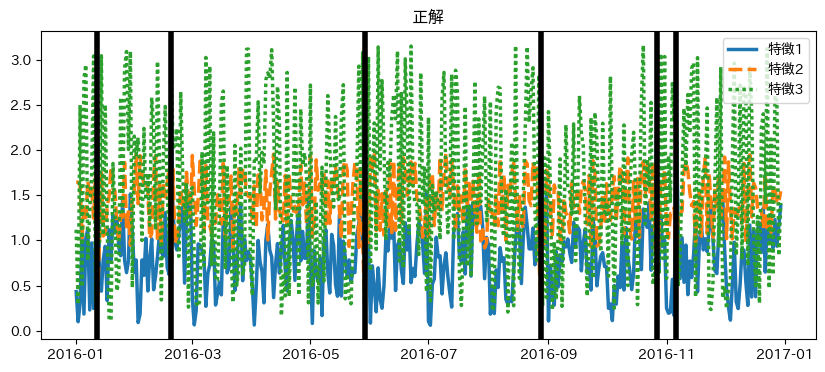
検出した日付と正解の比較
異常値として検出したタイミングと正解を比較します。
plt.figure(figsize=(10, 4))
plt.title("検出箇所")
sns.lineplot(data=data[column_names], palette="tab10", linewidth=2.5)
for d in data[data["is_anomaly"]].index:
plt.axvline(x=d, color="red", linewidth=4)
plt.figure(figsize=(10, 4))
plt.title("正解")
sns.lineplot(data=data[column_names], palette="tab10", linewidth=2.5)
for d in anomaly_dates:
plt.axvline(x=d, color="black", linewidth=4)
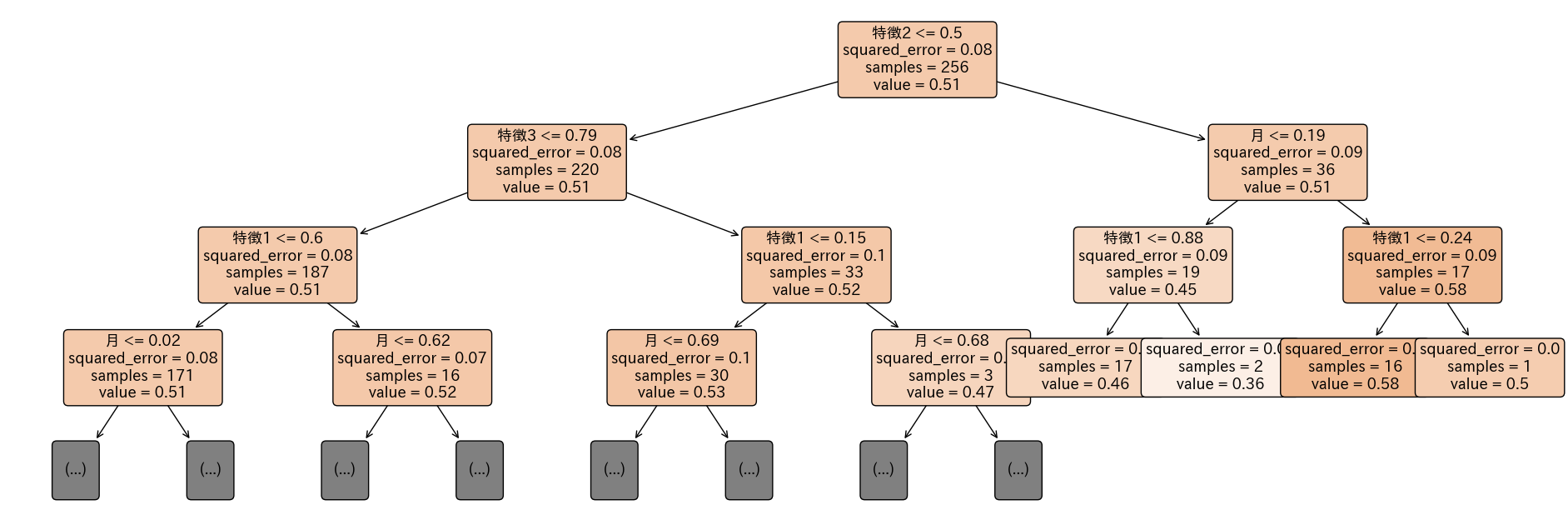
異常値のルール
サンプル数(samples)が1の分岐が一番右にあり、それは特徴1による分岐だと分かります。 実際、今回の異常値は特徴1が大きすぎる値のときに異常値になりやすいです。
plt.figure(figsize=(24, 8))
plot_tree(
ilf.estimators_[0],
feature_names=column_names,
filled=True,
fontsize=13,
max_depth=3,
precision=2,
rounded=True,
)
plt.show()