3.3.2
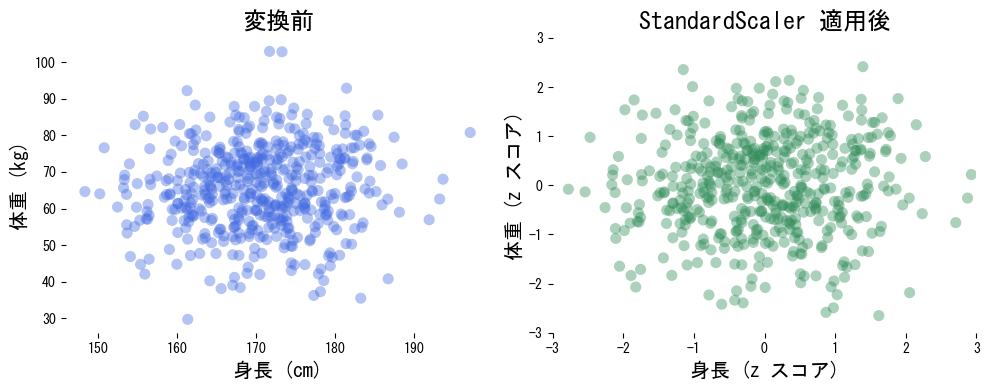
StandardScaler で平均0・分散1に正規化する
まとめ
- 各特徴量を平均 0・分散 1 の z スコアに標準化する。
sklearn.preprocessing.StandardScalerのfit_transformで変換し、inverse_transformで元のスケールに戻す。- SVM・k-NN・ロジスティック回帰など、距離や内積を利用するモデルの前処理として使う。
<p><b>StandardScaler</b> は各特徴量から平均を引き、標準偏差で割ることで平均 0・分散 1 のスケールに揃えます。距離や内積を利用する SVM、k-NN、ロジスティック回帰などでよく用いられる基本的な前処理です。</p>
定義 #
特徴量 (x) を平均 (\mu)、標準偏差 (\sigma) で正規化すると
$$ z = \frac{x - \mu}{\sigma} $$となります。with_mean=False で中心化のみ、with_std=False でスケーリングのみを選択できます。
実装例 #
| |
実務でのポイント #
scaler.mean_とscaler.scale_を保存し、推論時も同じ scaler インスタンスでtransformすることで情報漏洩を防ぎます。- 元のスケールに戻したいときは
scaler.inverse_transformを利用します。 - 疎行列を扱う場合は
with_mean=Falseを指定し、計算コストとスパース性を維持するのが無難です。 - 外れ値が多い場合は先にロバストなスケーリングを行ってから StandardScaler を適用すると安定します。