2.2.7
k-Vizinhos Mais Próximos (k-NN)
Resumo
- O k-NN armazena os dados de treinamento e faz previsões por votação majoritária entre os \(k\) vizinhos mais próximos de um ponto de consulta.
- Os principais hiperparâmetros são o número de vizinhos \(k\) e o esquema de ponderação por distância, que são fáceis de ajustar.
- Ele modela naturalmente fronteiras de decisão não lineares, mas as métricas de distância tornam-se menos informativas em altas dimensões (“a maldição da dimensionalidade”).
- A padronização de características ou a seleção de características informativas torna os cálculos de distância mais estáveis.
Intuição #
Este método deve ser interpretado por meio de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
Formulação Matemática #
Para um ponto de teste \(\mathbf{x}\), seja \(\mathcal{N}_k(\mathbf{x})\) o conjunto dos \(k\) vizinhos mais próximos no conjunto de treinamento. O voto para a classe \(c\) é
$$ v_c = \sum_{i \in \mathcal{N}_k(\mathbf{x})} w_i \,\mathbb{1}(y_i = c), $$onde os pesos \(w_i\) podem ser uniformes ou uma função da distância (por exemplo, distância inversa). A classe prevista é aquela com o maior número de votos.
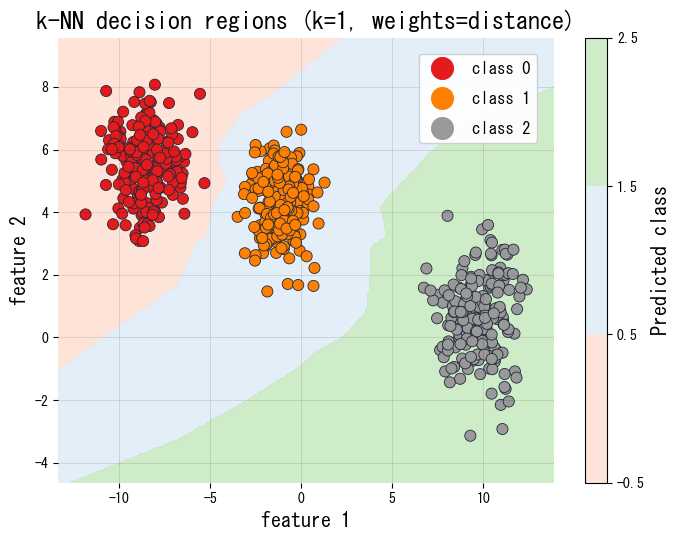
Experimentos em Python #
O trecho de código Python a seguir avalia vários números de vizinhos em uma divisão treino/validação e plota as regiões de decisão para o modelo com melhor desempenho.
| |
Referências #
- Cover, T. M., & Hart, P. E. (1967). Nearest Neighbor Pattern Classification. IEEE Transactions on Information Theory, 13(1), 21–27.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.