2.2.4
Análise Discriminante Linear (LDA)
Resumo
- A LDA encontra direções que maximizam a razão entre a variância entre classes e a variância dentro das classes, servindo tanto para classificação quanto para redução de dimensionalidade.
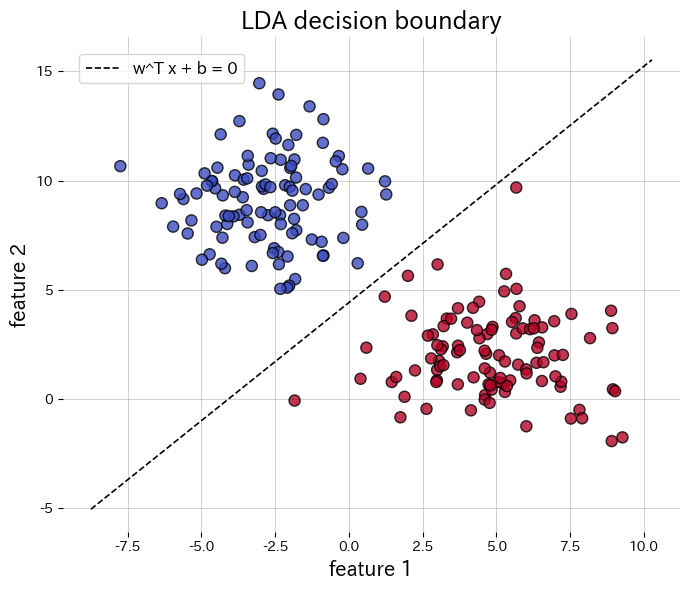
- A fronteira de decisão tem a forma \(\mathbf{w}^\top \mathbf{x} + b = 0\), que se torna uma reta em 2D ou um plano em 3D, fornecendo uma interpretação geométrica clara.
- Assumindo que cada classe segue uma distribuição gaussiana com a mesma matriz de covariância, a LDA se aproxima do classificador ótimo de Bayes.
- A
LinearDiscriminantAnalysisdo scikit-learn facilita a visualização das fronteiras de decisão e a inspeção das características projetadas.
Intuição #
Este método deve ser interpretado por meio de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
Formulação Matemática #
Para o caso de duas classes, a direção de projeção \(\mathbf{w}\) maximiza
$$ J(\mathbf{w}) = \frac{\mathbf{w}^\top \mathbf{S}_B \mathbf{w}}{\mathbf{w}^\top \mathbf{S}_W \mathbf{w}}, $$onde \(\mathbf{S}_B\) é a matriz de dispersão entre classes e \(\mathbf{S}_W\) é a matriz de dispersão dentro das classes. No caso multiclasse, obtemos até \(K-1\) direções de projeção, que podem ser usadas para redução de dimensionalidade.
Experimentos em Python #
Abaixo aplicamos a LDA a um conjunto de dados sintético de duas classes, traçamos a fronteira de decisão e plotamos as características projetadas em 1D. A chamada de transform retorna diretamente os dados projetados.
| |
Referências #
- Fisher, R. A. (1936). The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7(2), 179–188.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.