2.2.1
Regressão Logística
Resumo
- A regressão logística passa uma combinação linear das entradas pela função sigmoide para prever a probabilidade de que o rótulo seja 1.
- A saída pertence ao intervalo \([0, 1]\), permitindo definir limiares de decisão de forma flexível e interpretar os coeficientes como contribuições para as log-chances.
- O treinamento minimiza a perda de entropia cruzada (equivalentemente maximiza a log-verossimilhança); a regularização L1/L2 evita o sobreajuste do modelo.
- A
LogisticRegressiondo scikit-learn lida com pré-processamento, treinamento e visualização da fronteira de decisão com poucas linhas de código.
Intuição #
Este método deve ser interpretado por meio de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
Formulação Matemática #
A probabilidade da classe 1 dado \(\mathbf{x}\) é
$$ P(y=1 \mid \mathbf{x}) = \sigma(\mathbf{w}^\top \mathbf{x} + b) = \frac{1}{1 + \exp\left(-(\mathbf{w}^\top \mathbf{x} + b)\right)}. $$O aprendizado maximiza a log-verossimilhança
$$ \ell(\mathbf{w}, b) = \sum_{i=1}^{n} \Bigl[ y_i \log p_i + (1 - y_i) \log (1 - p_i) \Bigr], \quad p_i = \sigma(\mathbf{w}^\top \mathbf{x}_i + b), $$ou equivalentemente minimiza a perda de entropia cruzada negativa. Adicionar regularização L2 evita que os coeficientes explodam, enquanto a regularização L1 pode levar pesos irrelevantes até zero.
Experimentos em Python #
O trecho de código abaixo ajusta a regressão logística a um conjunto de dados sintético bidimensional e visualiza a fronteira de decisão resultante. Tudo — do treinamento à plotagem — cabe em poucas linhas graças ao scikit-learn.
| |
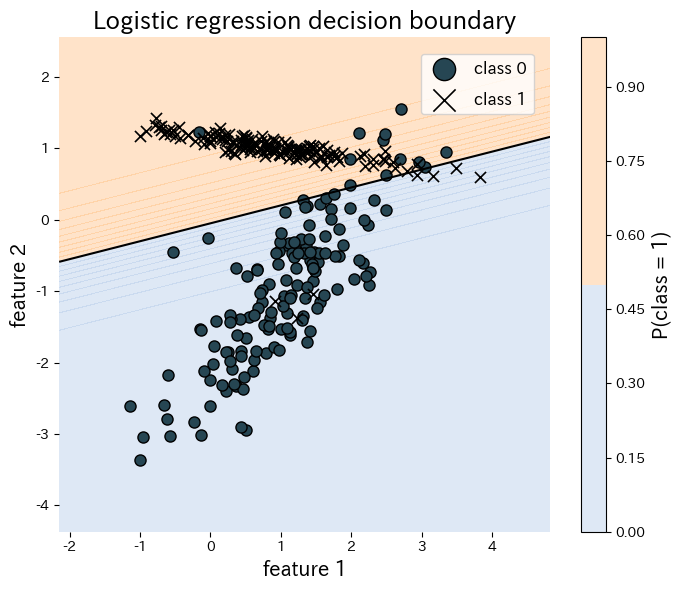
Referências #
- Agresti, A. (2015). Foundations of Linear and Generalized Linear Models. Wiley.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.