2.2.3
Perceptron
Resumo
- O perceptron converge em um número finito de atualizações em dados linearmente separáveis, tornando-o um dos algoritmos de classificação mais antigos.
- As previsões usam o sinal de uma soma ponderada \(\mathbf{w}^\top \mathbf{x} + b\); se o sinal estiver errado, a amostra correspondente atualiza os pesos.
- A regra de atualização — adicionar a amostra classificada incorretamente escalada pela taxa de aprendizado — fornece uma introdução intuitiva aos métodos baseados em gradiente.
- Quando os dados não são linearmente separáveis, é necessária a expansão de características ou truques de kernel.
Intuição #
Este método deve ser interpretado por meio de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
Formulação Matemática #
As previsões são calculadas como
$$ \hat{y} = \operatorname{sign}(\mathbf{w}^\top \mathbf{x} + b). $$Se uma amostra \((\mathbf{x}_i, y_i)\) for classificada incorretamente, atualizamos os parâmetros via
$$ \mathbf{w} \leftarrow \mathbf{w} + \eta\, y_i\, \mathbf{x}_i,\qquad b \leftarrow b + \eta\, y_i. $$Quando os dados são linearmente separáveis, este procedimento tem convergência garantida.
Experimentos em Python #
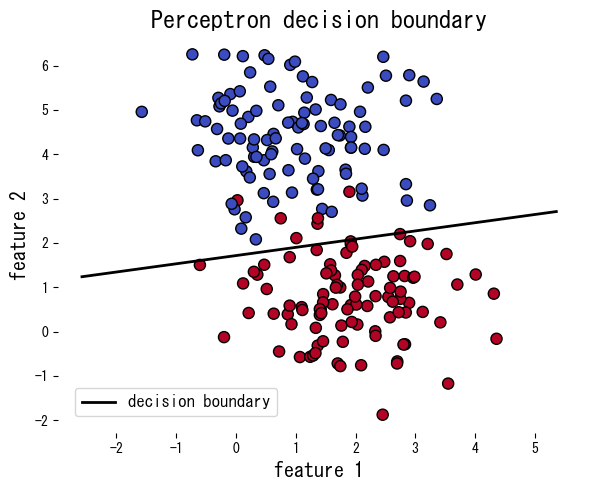
O exemplo a seguir aplica o perceptron a dados sintéticos, reportando o número de erros por época e plotando a fronteira de decisão resultante.
| |
Referências #
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, 65(6), 386–408.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.