2.2.5
Máquinas de Vetores de Suporte (SVM)
Resumo
- As SVM aprendem uma fronteira de decisão que maximiza a margem entre classes, enfatizando a generalização.
- Margens suaves introduzem variáveis de folga para que algumas classificações incorretas sejam permitidas, enquanto a penalidade \(C\) equilibra a largura da margem e os erros.
- Os truques de kernel substituem produtos internos por funções kernel, permitindo fronteiras de decisão não lineares sem expansão explícita de características.
- A padronização de características e o ajuste de hiperparâmetros (por exemplo, \(C\), \(\gamma\)) são cruciais para um bom desempenho.
Intuição #
Este método deve ser interpretado por meio de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
Formulação Matemática #
Para dados linearmente separáveis, resolvemos
$$ \min_{\mathbf{w}, b} \ \frac{1}{2} \lVert \mathbf{w} \rVert_2^2 \quad \text{s.t.} \quad y_i(\mathbf{w}^\top \mathbf{x}_i + b) \ge 1. $$Na prática, usamos a variante de margem suave com variáveis de folga \(\xi_i \ge 0\):
$$ \min_{\mathbf{w}, b, \boldsymbol{\xi}} \ \frac{1}{2} \lVert \mathbf{w} \rVert_2^2 + C \sum_{i=1}^{n} \xi_i \quad \text{s.t.} \quad y_i(\mathbf{w}^\top \mathbf{x}_i + b) \ge 1 - \xi_i. $$Substituir os produtos internos \(\mathbf{x}_i^\top \mathbf{x}_j\) por kernels \(K(\mathbf{x}_i, \mathbf{x}_j)\) resulta em fronteiras de decisão não lineares.
Experimentos em Python #
O código abaixo ajusta SVM com kernel linear e com kernel RBF em um conjunto de dados não linearmente separável gerado por make_moons. O kernel RBF captura muito melhor a fronteira curva.
| |
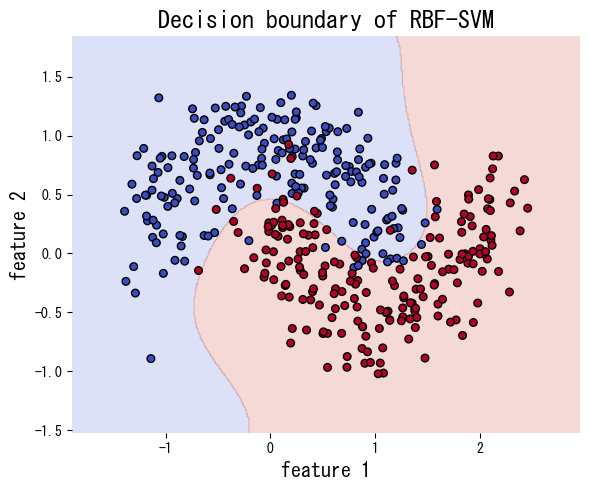
Referências #
- Vapnik, V. (1998). Statistical Learning Theory. Wiley.
- Smola, A. J., & Schölkopf, B. (2004). A Tutorial on Support Vector Regression. Statistics and Computing, 14(3), 199–222.