2.5.4
DBSCAN
- O DBSCAN (Density-Based Spatial Clustering of Applications with Noise) agrupa pontos de acordo com a densidade local, de modo que os clusters podem ter qualquer formato enquanto regiões esparsas se tornam ruído.
- Dois hiperparâmetros controlam o modelo:
eps, o raio da vizinhança, emin_samples, o número mínimo de vizinhos necessários para que um ponto se torne uma amostra central. - Os pontos são classificados como centrais, de fronteira ou ruído; os clusters são componentes conexas de pontos centrais mais seus vizinhos de fronteira.
- Uma receita comum de ajuste é fixar
min_samples(≥ dimensionalidade + 1) e varrerepsenquanto se inspeciona a proporção de pontos marcados como ruído.
Intuição #
Este método deve ser interpretado por meio de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
1. Visão geral #
O DBSCAN não requer o número de clusters antecipadamente. Em vez disso, ele inspeciona cada amostra:
- Pontos centrais: pelo menos
min_samplesvizinhos dentro da distânciaeps. - Pontos de fronteira: estão dentro da esfera
epsde um ponto central, mas não atendem ao critério central por si mesmos. - Pontos de ruído: não pertencem a nenhuma vizinhança central.
Por causa dessa visão baseada em densidade, o DBSCAN é robusto a clusters não convexos, como duas meias-luas ou círculos concêntricos. Sempre normalize os atributos para que eps tenha uma interpretação significativa.
2. Definição formal #
Dado (x_i \in \mathcal{X}), sua (\varepsilon)-vizinhança é
$$ \mathcal{N}_\varepsilon(x_i) = \{ x_j \in \mathcal{X} \mid \lVert x_i - x_j \rVert \le \varepsilon \}. $$Se (|\mathcal{N}_\varepsilon(x_i)| \ge \texttt{min_samples}|), o ponto é central. O DBSCAN constrói clusters explorando pontos alcançáveis por densidade; qualquer ponto não visitado se torna ruído. Com um índice espacial, a complexidade geral é (O(n \log n)).
3. Exemplo em Python #
O trecho abaixo usa o DBSCAN do scikit-learn em um conjunto de dados de duas meias-luas, colore os pontos centrais/de fronteira de forma diferente e informa quantas amostras são marcadas como ruído.
| |
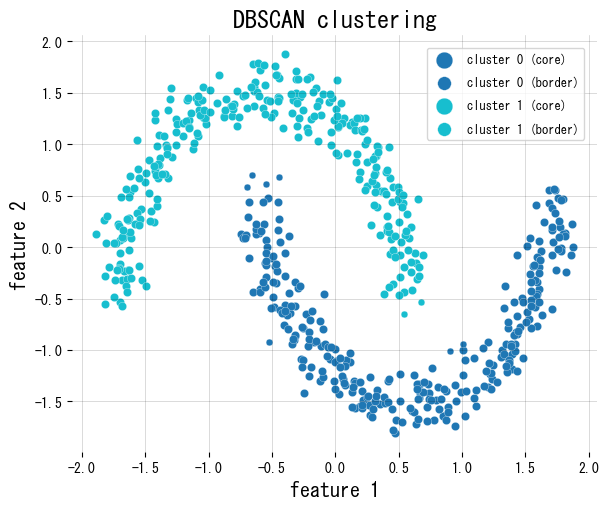
4. Dicas práticas #
- Plote as distâncias ordenadas ao k-ésimo vizinho (k =
min_samples) para escolher oepsonde a curva apresenta um cotovelo. - Use pipelines para que a normalização e o agrupamento sejam executados juntos; caso contrário, as decisões baseadas em distância perdem o significado.
- Para conjuntos de dados muito grandes, considere vizinhos mais próximos aproximados ou mude para o HDBSCAN, que estende o DBSCAN para dados de múltiplas densidades e elimina a necessidade de ajustar o
eps.
5. Referências #
- Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. (1996). A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. KDD.
- Schubert, E., Sander, J., Ester, M., Kriegel, H.-P., & Xu, X. (2017). DBSCAN Revisited, Revisited. ACM Transactions on Database Systems.
- scikit-learn developers. (2024). Clustering. https://scikit-learn.org/stable/modules/clustering.html