2.5.5
Modelos de Mistura Gaussiana (GMM)
Resumo
- Um Modelo de Mistura Gaussiana representa os dados como uma soma ponderada de componentes normais multivariadas.
- Ele produz uma matriz de responsabilidades que quantifica o quanto cada componente explica cada amostra.
- Os parâmetros são estimados com o algoritmo EM; as estruturas de covariância podem ser
full,tied,diagouspherical. - A seleção de modelo tipicamente combina critérios de informação (BIC/AIC) com múltiplas inicializações aleatórias para estabilidade.
Intuição #
Este método deve ser interpretado por meio de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
Formulação Matemática #
A densidade de \(\mathbf{x}\) é
$$ p(\mathbf{x}) = \sum_{k=1}^{K} \pi_k \, \mathcal{N}(\mathbf{x} \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k), $$com pesos de mistura \(\pi_k\) (não negativos e com soma igual a 1). O EM alterna:
- Etapa E: calcular responsabilidades \(\gamma_{ik}\). $$ \gamma_{ik} = \frac{\pi_k \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)} {\sum_{j=1}^K \pi_j \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)}. $$
- Etapa M: re-estimar \(\pi_k, \boldsymbol{\mu}_k, \boldsymbol{\Sigma}k\) usando \(\gamma{ik}\) como pesos.
A log-verossimilhança aumenta monotonicamente e converge para um ótimo local.
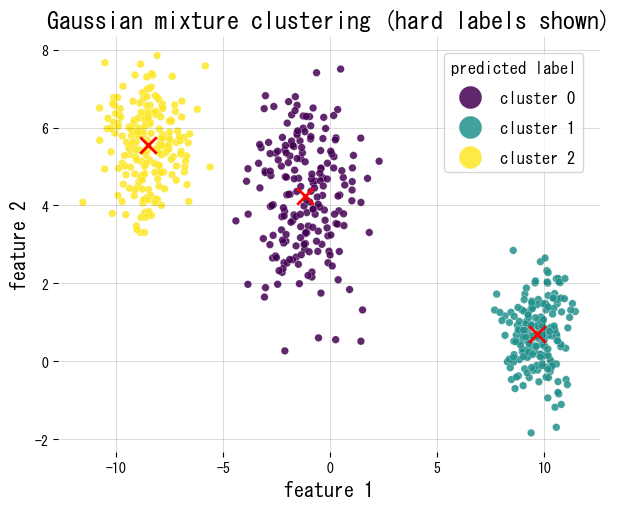
Experimentos em Python #
Ajustamos um GMM a blobs sintéticos em 2D, plotamos as atribuições rígidas e reportamos os pesos de mistura e o formato da matriz de responsabilidades.
| |
Referências #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society, Series B.
- scikit-learn developers. (2024). Gaussian Mixture Models. https://scikit-learn.org/stable/modules/mixture.html