2.1.6
Regressão Linear Bayesiana
- A regressão linear Bayesiana trata os coeficientes como variáveis aleatórias, estimando tanto as previsões quanto sua incerteza.
- A distribuição a posteriori é derivada analiticamente a partir da priori e da verossimilhança, tornando o método robusto para conjuntos de dados pequenos ou ruidosos.
- A distribuição preditiva é Gaussiana, então sua média e variância podem ser visualizadas e usadas para tomada de decisões.
- O
BayesianRidgeno scikit-learn ajusta automaticamente a variância do ruído, o que simplifica a adoção prática.
Intuição #
Este método deve ser interpretado por meio de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
Formulação Matemática #
Assumimos uma priori Gaussiana multivariada com média 0 e variância \(\tau^{-1}\) para o vetor de coeficientes \(\boldsymbol\beta\), e ruído Gaussiano \(\epsilon_i \sim \mathcal{N}(0, \alpha^{-1})\) nas observações. A posteriori se torna
$$ p(\boldsymbol\beta \mid \mathbf{X}, \mathbf{y}) = \mathcal{N}(\boldsymbol\beta \mid \boldsymbol\mu, \mathbf{\Sigma}) $$com
$$ \mathbf{\Sigma} = (\alpha \mathbf{X}^\top \mathbf{X} + \tau \mathbf{I})^{-1}, \qquad \boldsymbol\mu = \alpha \mathbf{\Sigma} \mathbf{X}^\top \mathbf{y}. $$A distribuição preditiva para uma nova entrada \(\mathbf{x}*\) também é Gaussiana, \(\mathcal{N}(\hat{y}, \sigma_^2)\). O BayesianRidge estima \(\alpha\) e \(\tau\) a partir dos dados, então você pode usar o modelo sem ajustá-los manualmente.
Experimentos em Python #
O exemplo a seguir compara os mínimos quadrados ordinários com a regressão linear Bayesiana em dados contendo valores atípicos.
| |
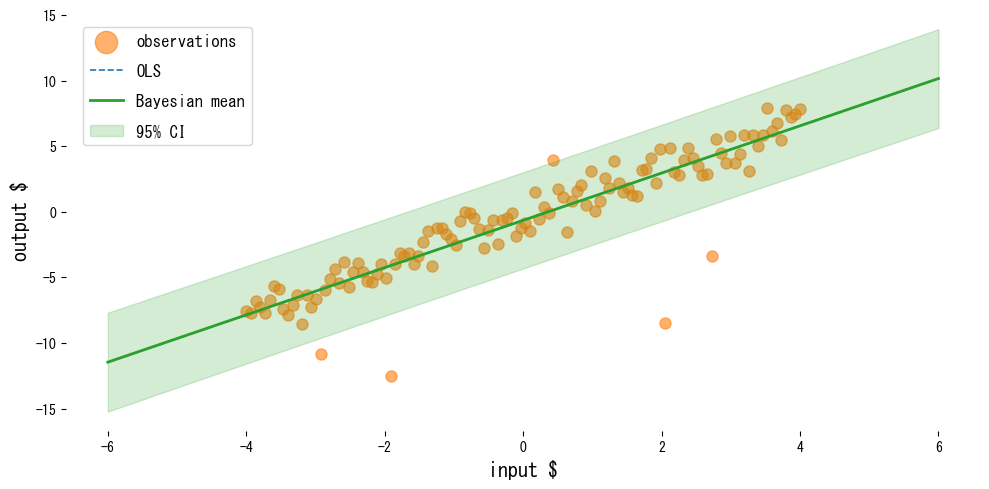
Leitura dos resultados #
- O OLS é puxado em direção aos valores atípicos, enquanto a regressão linear Bayesiana mantém a previsão média mais estável.
- Usando
return_std=Trueobtemos o desvio padrão preditivo, o que facilita a plotagem de intervalos de credibilidade. - A inspeção da variância a posteriori destaca quais coeficientes carregam maior incerteza.
Referências #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press.