2.1.1
Regressão Linear
Resumo
- A regressão linear modela a relação linear entre entradas e saídas e fornece uma base de referência que é tanto preditiva quanto interpretável.
- O método dos mínimos quadrados ordinários estima os coeficientes minimizando a soma dos resíduos quadráticos, produzindo uma solução de forma fechada.
- A inclinação nos diz quanto a saída muda quando a entrada aumenta em uma unidade, enquanto o intercepto representa o valor esperado quando a entrada é zero.
- Quando o ruído ou os valores atípicos são grandes, considere a padronização e variantes robustas para que o pré-processamento e a avaliação permaneçam confiáveis.
Intuição #
Este método deve ser interpretado por meio de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
Formulação Matemática #
Um modelo linear univariado é escrito como
$$ y = w x + b. $$Minimizando a soma dos resíduos quadráticos \(\epsilon_i = y_i - (w x_i + b)\)
$$ L(w, b) = \sum_{i=1}^{n} \big(y_i - (w x_i + b)\big)^2, $$obtemos a solução analítica
$$ w = \frac{\sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^{n} (x_i - \bar{x})^2}, \qquad b = \bar{y} - w \bar{x}, $$onde \(\bar{x}\) e \(\bar{y}\) são as médias de \(x\) e \(y\). A mesma ideia se estende à regressão multivariada com vetores e matrizes.
Experimentos em Python #
O código a seguir ajusta uma reta de regressão simples com o scikit-learn e plota o resultado. O código é idêntico à página em japonês, então as figuras correspondem entre idiomas.
| |
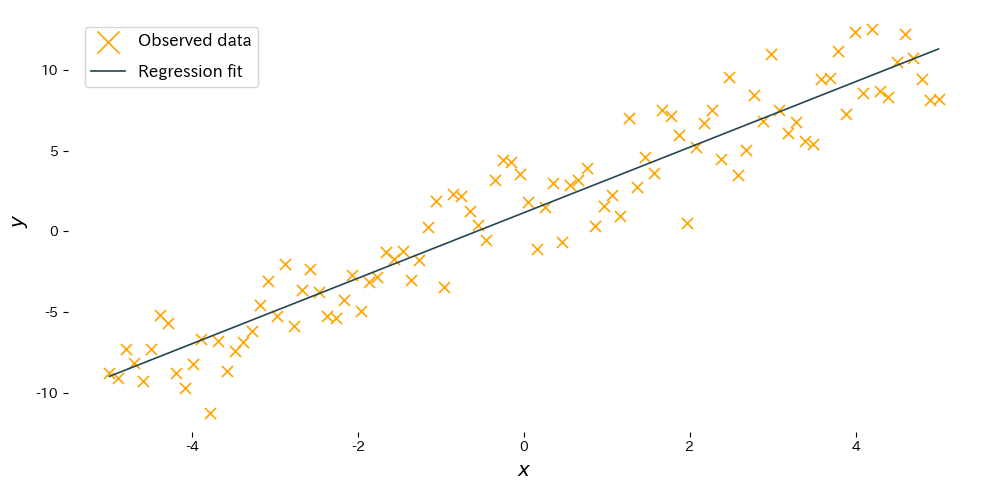
Leitura dos resultados #
- Inclinação \(w\): indica quanto a saída aumenta ou diminui quando a entrada cresce em uma unidade. A estimativa deve estar próxima da inclinação verdadeira.
- Intercepto \(b\): mostra a saída esperada quando a entrada é 0, ajustando a posição vertical da reta.
- A padronização das características com
StandardScalerestabiliza o aprendizado quando as entradas variam em escala.
Referências #
- Draper, N. R., & Smith, H. (1998). Applied Regression Analysis (3rd ed.). John Wiley & Sons.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.