2.1.9
Regressão por Mínimos Quadrados Parciais (PLS)
Resumo
- O método de Mínimos Quadrados Parciais (PLS) extrai fatores latentes que maximizam a covariância entre preditores e o alvo antes de realizar a regressão.
- Diferentemente do PCA, os eixos aprendidos incorporam informações do alvo, preservando o desempenho preditivo enquanto reduzem a dimensionalidade.
- O ajuste do número de fatores latentes estabiliza modelos na presença de forte multicolinearidade.
- A inspeção dos carregamentos revela quais combinações de variáveis estão mais relacionadas com o alvo.
Intuição #
Este método deve ser interpretado através de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
Formulação Matemática #
Dada uma matriz de preditores \(\mathbf{X}\) e um vetor de resposta \(\mathbf{y}\), o PLS alterna atualizações de escores latentes \(\mathbf{t} = \mathbf{X} \mathbf{w}\) e \(\mathbf{u} = \mathbf{y} c\) de modo que sua covariância \(\mathbf{t}^\top \mathbf{u}\) seja maximizada. A repetição deste procedimento produz um conjunto de fatores latentes sobre os quais um modelo de regressão linear
$$ \hat{y} = \mathbf{t} \boldsymbol{b} + b_0 $$é ajustado. O número de fatores \(k\) é tipicamente escolhido por validação cruzada.
Experimentos em Python #
Comparamos o desempenho do PLS para diferentes números de fatores latentes no conjunto de dados de aptidão física Linnerud.
| |
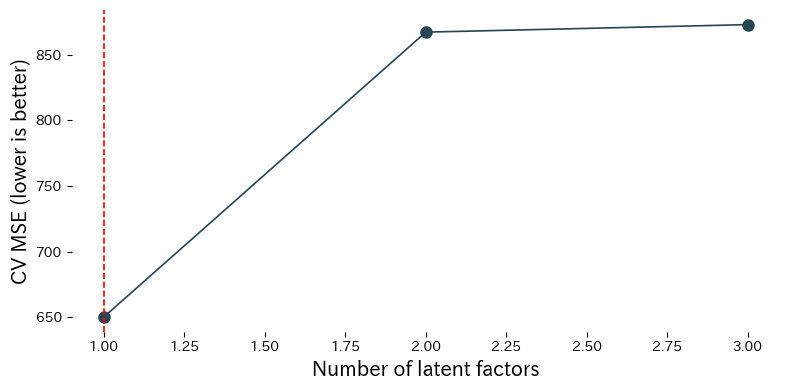
Interpretação dos resultados #
- O MSE por validação cruzada diminui à medida que fatores são adicionados, atinge um mínimo e depois piora se você continuar adicionando mais.
- A inspeção de
x_loadings_ey_loadings_mostra quais variáveis contribuem mais para cada fator latente. - A padronização das entradas garante que variáveis medidas em diferentes escalas contribuam igualmente.
Referências #
- Wold, H. (1975). Soft Modelling by Latent Variables: The Non-Linear Iterative Partial Least Squares (NIPALS) Approach. In Perspectives in Probability and Statistics. Academic Press.
- Geladi, P., & Kowalski, B. R. (1986). Partial Least-Squares Regression: A Tutorial. Analytica Chimica Acta, 185, 1–17.