2.1.4
Regressão Polinomial
Resumo
- A regressão polinomial expande as características com potências para que um modelo linear possa ajustar relações não lineares.
- O modelo permanece uma combinação linear de coeficientes, preservando soluções de forma fechada e interpretabilidade.
- Graus mais altos aumentam a expressividade, mas também convidam ao sobreajuste, tornando a regularização e a validação cruzada importantes.
- A padronização das características e o ajuste do grau junto com a intensidade da penalidade levam a previsões estáveis.
Intuição #
Este método deve ser interpretado por meio de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
Formulação Matemática #
Dado \(\mathbf{x} = (x_1, \dots, x_m)\), construímos um vetor de características polinomiais \(\phi(\mathbf{x})\) até o grau \(d\) e ajustamos uma regressão linear sobre ele. Para \(m = 2\) e \(d = 2\),
$$ \phi(\mathbf{x}) = (1, x_1, x_2, x_1^2, x_1 x_2, x_2^2), $$e o modelo se torna
$$ y = \mathbf{w}^\top \phi(\mathbf{x}). $$Conforme \(d\) cresce, o número de termos aumenta rapidamente, então na prática começamos com grau 2 ou 3 e o combinamos com regularização (por exemplo, Ridge) quando necessário.
Experimentos em Python #
Abaixo adicionamos características polinomiais de terceiro grau e ajustamos uma curva a dados gerados a partir de uma função cúbica com ruído.
| |
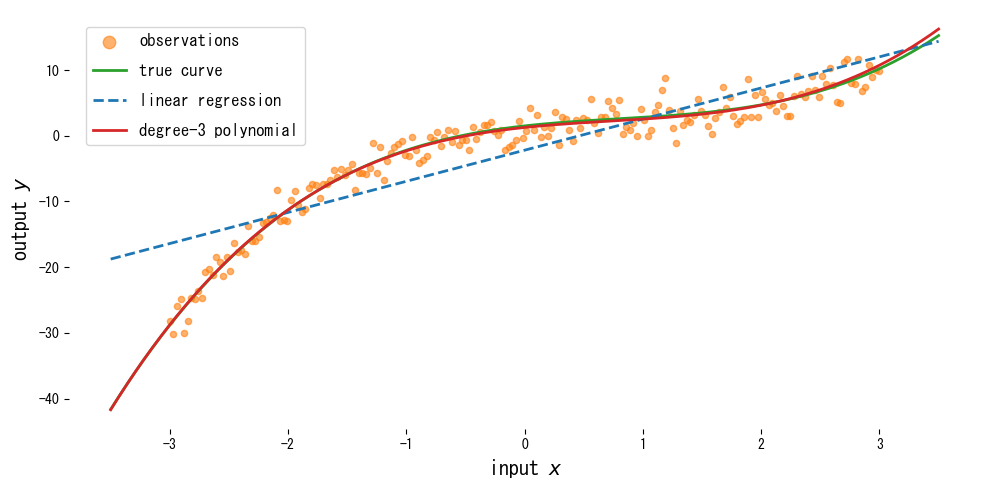
Leitura dos resultados #
- A regressão linear simples perde a curvatura, especialmente perto do centro, enquanto o polinômio cúbico segue de perto a curva verdadeira.
- Aumentar o grau melhora o ajuste nos dados de treinamento, mas pode tornar a extrapolação instável.
- Combinar características polinomiais com uma regressão regularizada (por exemplo, Ridge) via pipeline ajuda a conter o sobreajuste.
Referências #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.