2.1.8
Regressão por Componentes Principais (PCR)
Resumo
- A Regressão por Componentes Principais (PCR) aplica PCA para comprimir variáveis antes de ajustar a regressão linear, reduzindo a instabilidade causada pela multicolinearidade.
- Os componentes principais priorizam direções com grande variância, filtrando eixos ruidosos enquanto preservam a estrutura informativa.
- A escolha de quantos componentes manter equilibra o risco de sobreajuste e o custo computacional.
- O pré-processamento adequado — padronização e tratamento de valores ausentes — estabelece a base para precisão e interpretabilidade.
Intuição #
Este método deve ser interpretado através de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
Formulação Matemática #
Aplique PCA à matriz de design padronizada \(\mathbf{X}\) e retenha os \(k\) principais autovetores. Com os escores dos componentes principais \(\mathbf{Z} = \mathbf{X} \mathbf{W}_k\), o modelo de regressão
$$ y = \boldsymbol{\gamma}^\top \mathbf{Z} + b $$é aprendido. Os coeficientes no espaço original de variáveis são recuperados via \(\boldsymbol{\beta} = \mathbf{W}_k \boldsymbol{\gamma}\). O número de componentes \(k\) é selecionado usando a variância explicada acumulada ou validação cruzada.
Experimentos em Python #
Avaliamos os escores de validação cruzada da PCR no conjunto de dados diabetes à medida que variamos o número de componentes.
| |
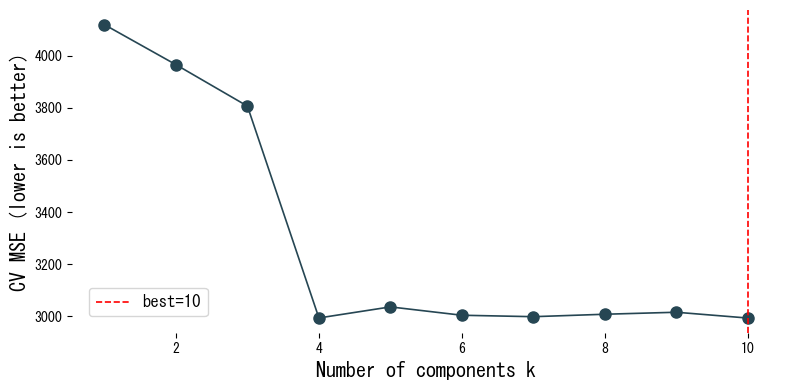
Interpretação dos resultados #
- À medida que o número de componentes aumenta, o ajuste de treino melhora, mas o MSE por validação cruzada atinge um mínimo em um valor intermediário.
- A inspeção da razão de variância explicada revela quanta variabilidade geral cada componente captura.
- Os carregamentos dos componentes indicam quais variáveis originais contribuem mais para cada direção principal.
Referências #
- Jolliffe, I. T. (2002). Principal Component Analysis (2nd ed.). Springer.
- Massy, W. F. (1965). Principal Components Regression in Exploratory Statistical Research. Journal of the American Statistical Association, 60(309), 234–256.