2.3.1
Árvore de Decisão (Classificador)
- Um classificador de árvore de decisão particiona o espaço de características com uma sequência de perguntas se-então, de modo que cada nó terminal contenha majoritariamente uma classe.
- A qualidade da divisão é medida com índices de impureza, como o índice Gini ou a entropia; escolha o índice que melhor reflete o custo de classificação incorreta para a sua tarefa.
- Controlar a profundidade, o número mínimo de amostras por nó ou a poda evita que a árvore memorize ruído, preservando a interpretabilidade.
- Visualizar tanto as regiões de decisão quanto a árvore aprendida ajuda a explicar o modelo para as partes interessadas.
Intuição #
Este método deve ser interpretado através de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
1. Visão Geral #
Árvores de decisão são modelos de aprendizado supervisionado que dividem recursivamente o espaço de entrada. Começando pela raiz, cada nó interno faz uma pergunta como “é (x_j \le s)?” e direciona a amostra para o próximo nó. Para classificação, queremos folhas o mais puras possível, ou seja, que contenham quase apenas uma única etiqueta de classe. O modelo final é, portanto, um livro de regras compacto que pode ser facilmente inspecionado ou convertido em lógica de negócios.
2. Medidas de impureza #
Seja (t) um nó e (p_k) a proporção da classe dentro desse nó. Dois índices de impureza comuns são
$$ \mathrm{Gini}(t) = 1 - \sum_k p_k^2, $$$$ H(t) = - \sum_k p_k \log p_k. $$Ao dividir o nó (t) na característica (x_j) com limiar (s), avaliamos o ganho
$$ \Delta I = I(t) - \frac{n_L}{n_t} I(t_L) - \frac{n_R}{n_t} I(t_R), $$onde (I(\cdot)) é o índice Gini ou a entropia, (t_L) e (t_R) são os nós filhos, e (n_t) é o número de amostras que chegam a (t). A divisão que maximiza (\Delta I) é selecionada.
3. Exemplo em Python #
O trecho de código abaixo gera um conjunto de dados de duas classes com make_classification, ajusta um DecisionTreeClassifier e visualiza suas regiões de decisão. Alterar o criterion de "gini" para "entropy" troca a medida de impureza.
| |
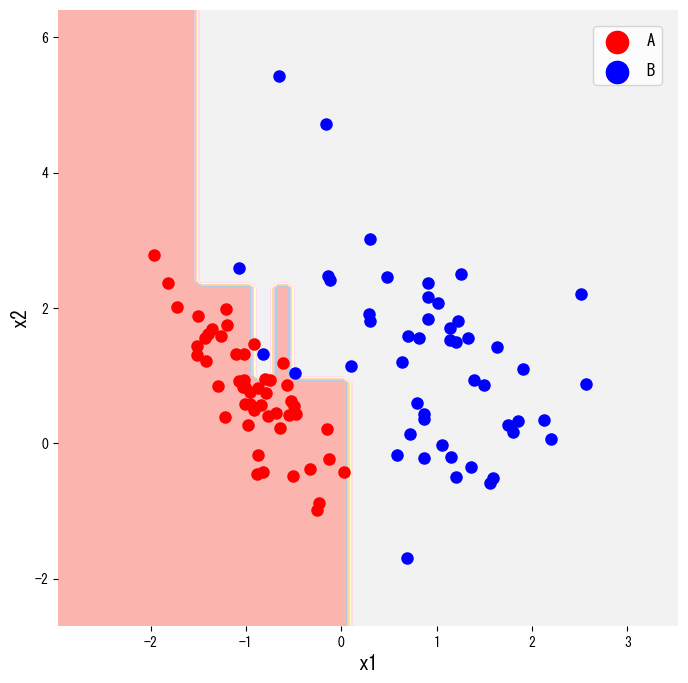
O mesmo estimador pode ser renderizado como um diagrama de árvore real com plot_tree, o que é conveniente para relatórios ou apresentações.
| |

4. Referências #
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth.
- scikit-learn developers. (2024). Decision Trees. https://scikit-learn.org/stable/modules/tree.html