2.3.2
Árvore de Decisão (Regressor)
- Árvores de regressão aproximam relações não lineares dividindo recursivamente o espaço de características até que cada folha possa ser representada por um único valor constante.
- As divisões minimizam o erro quadrático médio (MSE) dos filhos esquerdo e direito; a redução do MSE determina se uma pergunta é útil.
- Hiperparâmetros como
max_depth,min_samples_leafeccp_alphaequilibram a precisão com a interpretabilidade e ajudam a evitar sobreajuste. - Diagnósticos visuais–gráficos de dispersão, mapas de contorno e árvores renderizadas–facilitam a explicação de quais regiões compartilham a mesma predição.
Intuição #
Este método deve ser interpretado através de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
1. Visão Geral #
Assim como os classificadores, as árvores de regressão fazem perguntas simples sobre as características de entrada, mas o alvo é contínuo. Cada folha prediz uma constante (a média das amostras de treinamento que chegaram ali). Como a função é constante por partes, aumentar a profundidade captura estruturas cada vez mais detalhadas, enquanto árvores rasas enfatizam tendências suaves.
2. Critério de divisão (redução de variância) #
Para um nó (t) contendo (n_t) amostras e alvo médio (\bar{y}_t), a impureza é o MSE do nó:
$$ \mathrm{MSE}(t) = \frac{1}{n_t} \sum_{i \in t} (y_i - \bar{y}_t)^2. $$A divisão em (x_j) no limiar (s) produz filhos (t_L) e (t_R). A qualidade da divisão é medida por
$$ \Delta = \mathrm{MSE}(t) - \frac{n_L}{n_t} \mathrm{MSE}(t_L) - \frac{n_R}{n_t} \mathrm{MSE}(t_R). $$Escolhemos a divisão com o maior (\Delta); quando nenhuma divisão produz ganho positivo, o nó se torna uma folha.
3. Exemplo em Python #
O primeiro trecho ajusta uma árvore rasa a amostras ruidosas extraídas de uma curva senoidal para que possamos ver a natureza constante por partes da predição. Um segundo experimento treina um regressor com duas características, avalia (R^2), RMSE e MAE, e visualiza a superfície aprendida além da árvore final.
| |
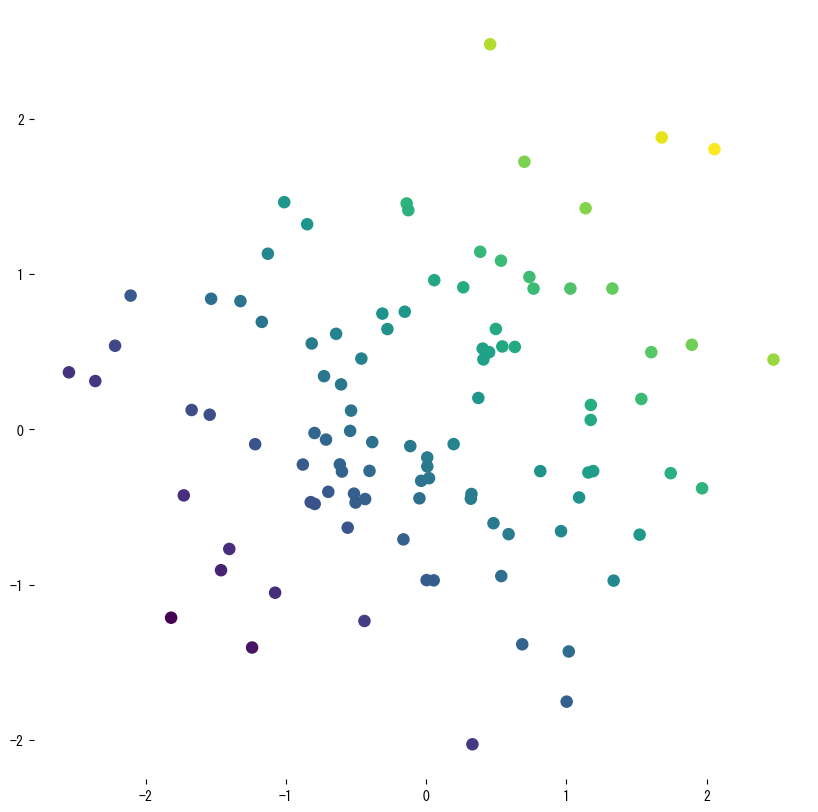
| |
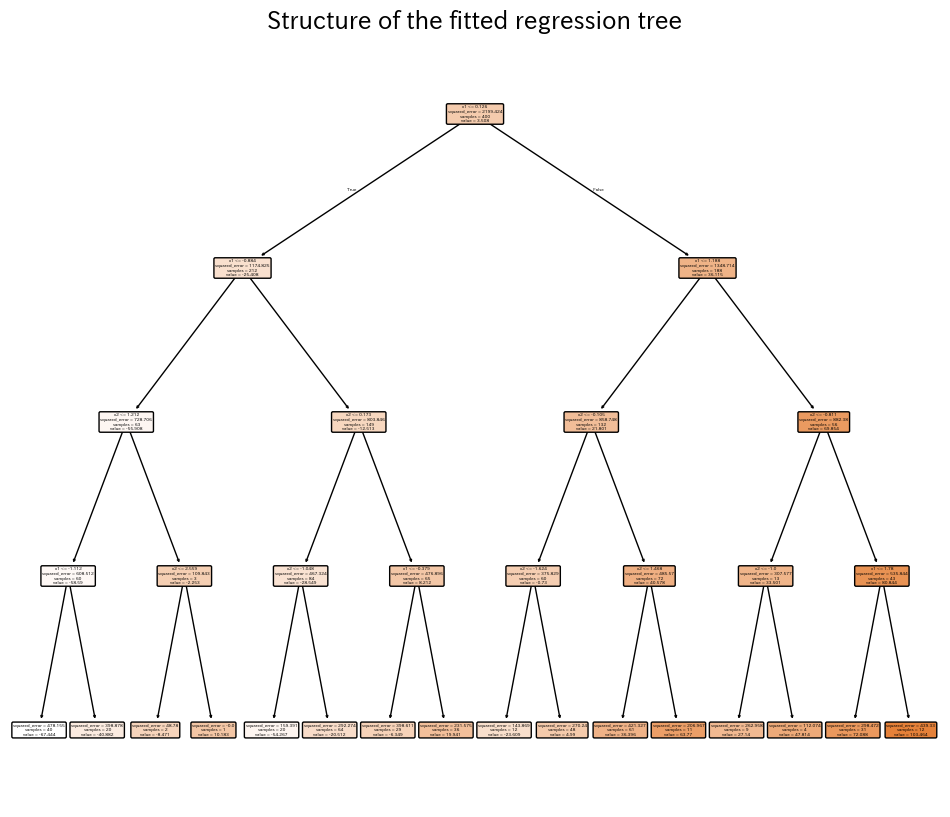
| |

4. Referências #
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth.
- scikit-learn developers. (2024). Decision Trees. https://scikit-learn.org/stable/modules/tree.html