2.3.3
Parâmetros de Árvore de Decisão
- Árvores de decisão oferecem diversas alavancas–profundidade, amostras mínimas por divisão/folha, poda e pesos de classe–que controlam diretamente sua capacidade e interpretabilidade.
max_depthemin_samples_leaflimitam quão detalhadas as regras podem se tornar, enquantoccp_alpha(poda de custo-complexidade) remove ramos cuja melhoria não justifica seu tamanho.- Escolher o critério certo (
squared_error,absolute_error,friedman_mse, etc.) muda o quão agressivamente a árvore reage a valores atípicos. - Diagnósticos visuais de fronteiras de decisão e estruturas de árvores ajudam a comunicar por que um determinado conjunto de hiperparâmetros funciona melhor.
Intuição #
Este método deve ser interpretado através de suas suposições, condições dos dados e como as escolhas de parâmetros afetam a generalização.
Explicação Detalhada #
1. Visão Geral #
Uma árvore de decisão cresce escolhendo repetidamente a divisão que produz a maior redução de impureza. Sem restrições, a árvore continua dividindo até que cada folha seja pura, o que frequentemente significa sobreajuste. Os hiperparâmetros atuam, portanto, como regularizadores: limites de profundidade mantêm a árvore rasa, contagens mínimas de amostras evitam folhas minúsculas, e a poda elimina ramos cuja contribuição é marginal.
2. Ganho de impureza e poda de custo-complexidade #
Para um nó pai (P) dividido em filhos (L) e (R), a redução de impureza é
$$ \Delta I = I(P) - \frac{|L|}{|P|} I(L) - \frac{|R|}{|P|} I(R), $$onde (I(\cdot)) pode ser o índice Gini, a entropia, o MSE ou o MAE dependendo da tarefa. Uma divisão só é mantida se (\Delta I > 0).
A poda de custo-complexidade avalia uma árvore inteira (T) com
$$ R_\alpha(T) = R(T) + \alpha |T|, $$onde (R(T)) é a perda de treinamento (por exemplo, erro quadrático total), (|T|) é o número de folhas, e (\alpha \ge 0) penaliza árvores grandes. Aumentar (\alpha) favorece estruturas mais simples.
3. Experimentos em Python #
O trecho abaixo treina vários modelos DecisionTreeRegressor em um conjunto de dados sintético e relata como diferentes hiperparâmetros afetam o (R^2) de treinamento e validação. Ajustar max_depth, min_samples_leaf ou ccp_alpha mostra como capacidade e generalização se equilibram.
| |
As figuras a seguir (compartilhadas com a página em japonês) ilustram como a variação de parâmetros-chave remodela a superfície de predição. Use-as como uma lista de verificação visual ao ajustar sua própria árvore:
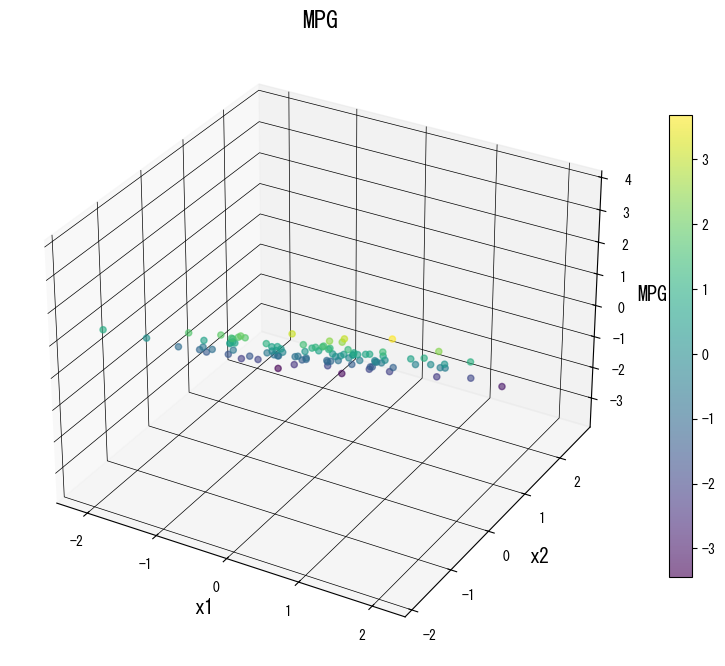
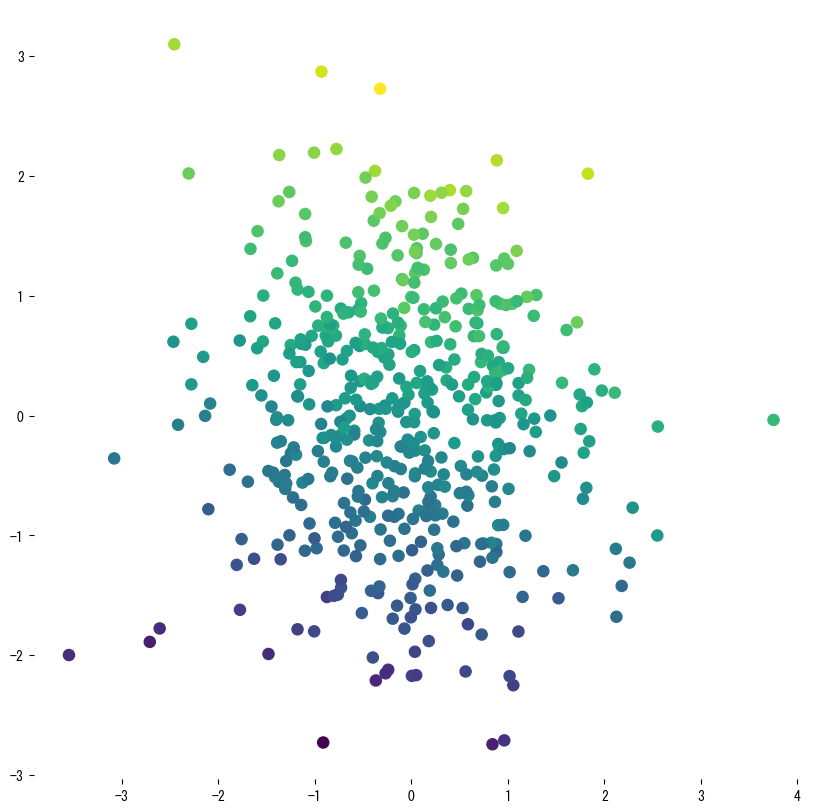
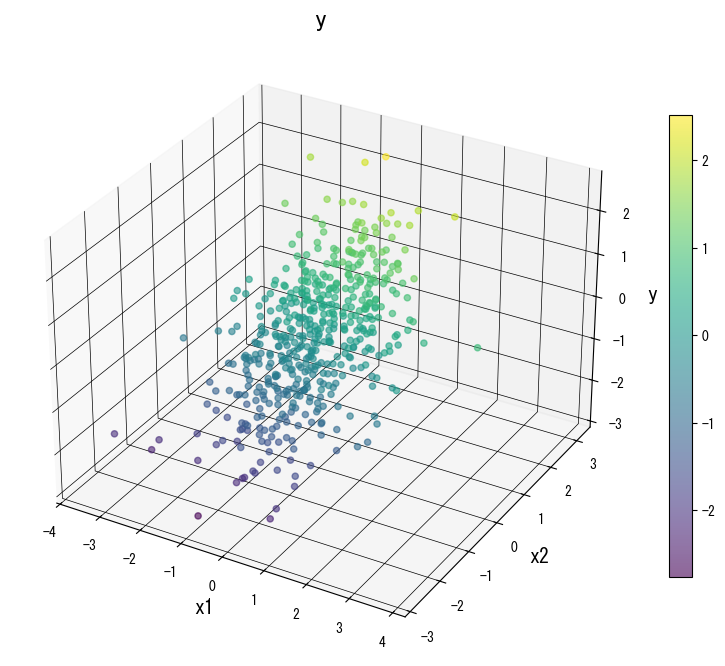
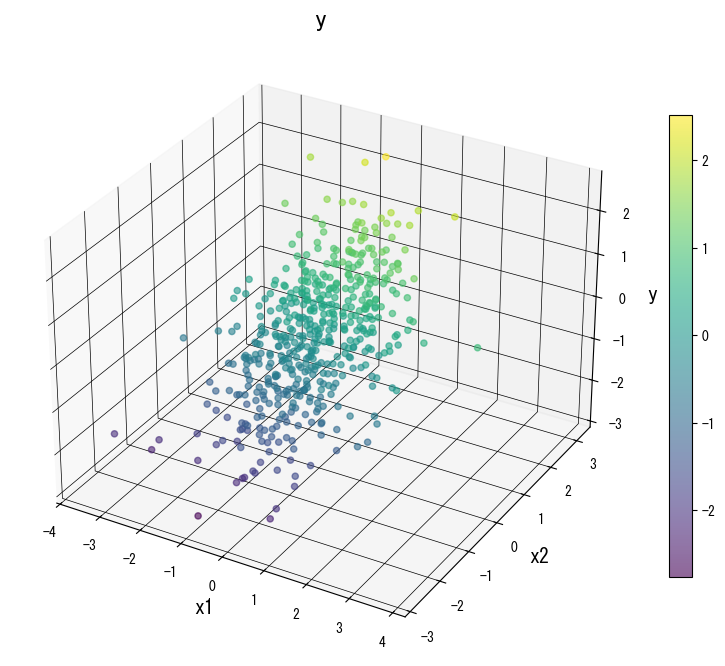
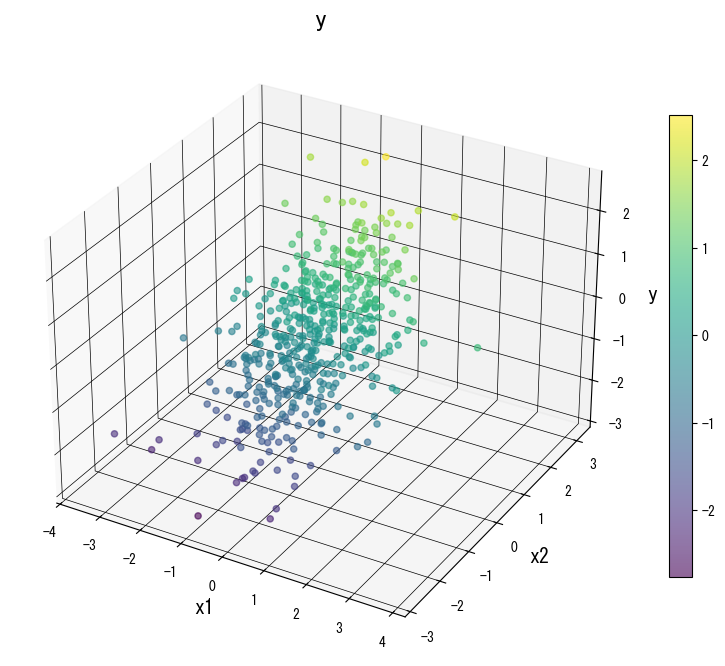
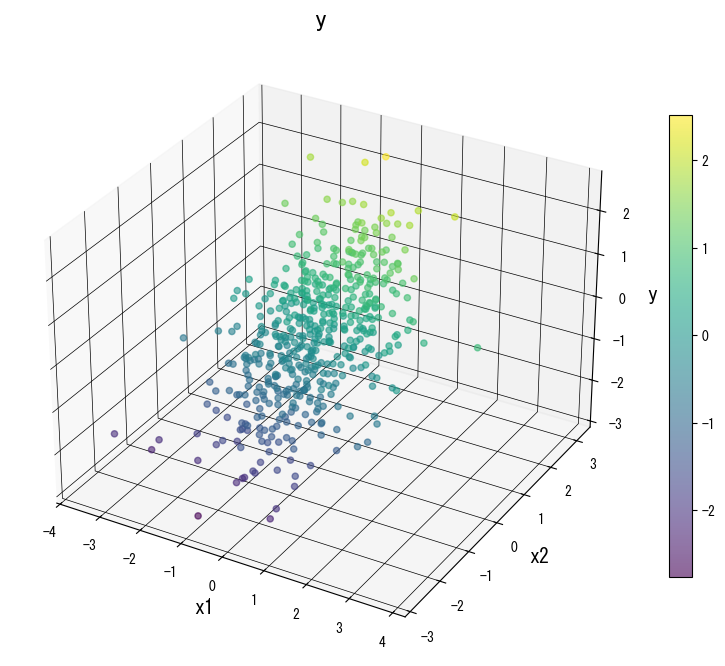
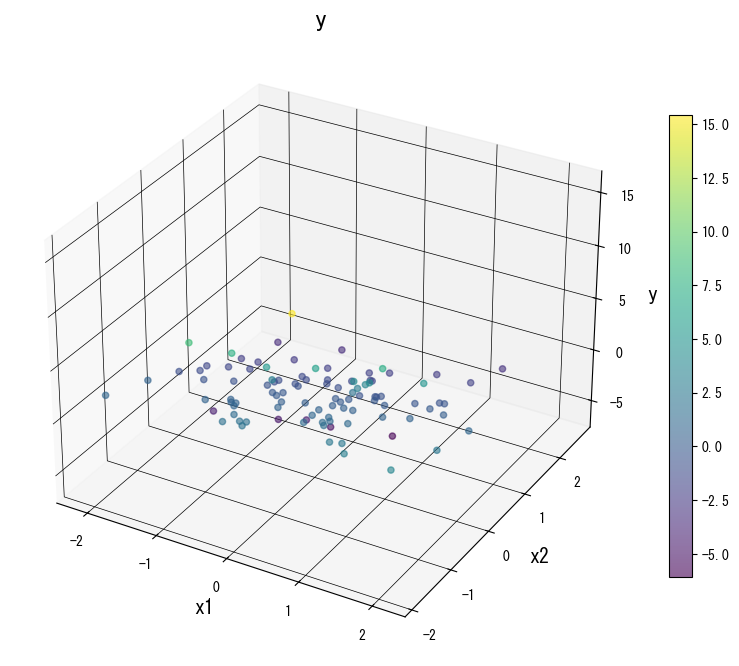
4. Referências #
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth.
- Breiman, L., & Friedman, J. H. (1991). Cost-Complexity Pruning. In Classification and Regression Trees. Chapman & Hall.
- scikit-learn developers. (2024). Decision Trees. https://scikit-learn.org/stable/modules/tree.html