2.2.4
Linear Discriminant Analysis
สรุป
- LDA หาเวกเตอร์ที่เพิ่มอัตราส่วนระหว่างความแปรปรวนระหว่างคลาสกับในคลาส จึงใช้ได้ทั้งจำแนกและลดมิติแบบมีผู้สอน
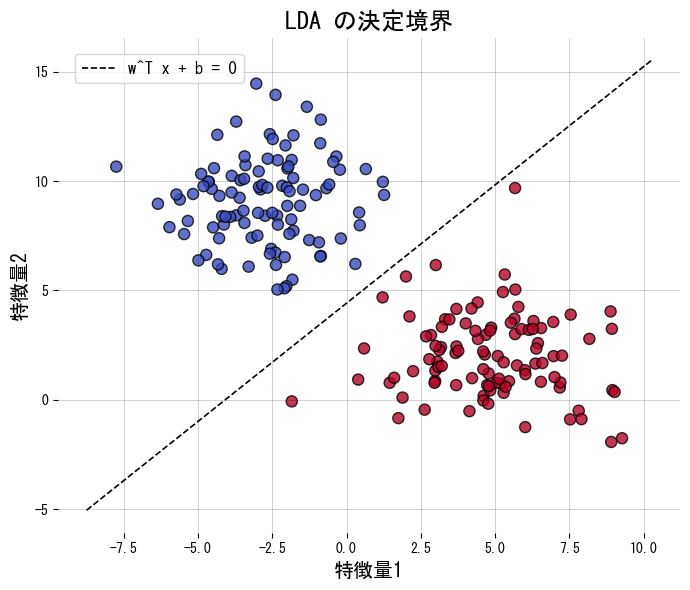
- เส้นแบ่งมีรูป \(\mathbf{w}^\top \mathbf{x} + b = 0\) ซึ่งตีความเป็นเส้นตรงหรือระนาบในมิติสูง
- หากสมมติว่าทุกคลาสเป็นแกาสเซียนที่มีเมทริกซ์โคเวเรียนซ์เท่ากันจะได้ตัวจำแนกที่เกือบเหมาะเชิงเบย์
LinearDiscriminantAnalysisใน scikit-learn ช่วยให้ฝึก วาดเส้นแบ่ง และดูฟีเจอร์หลังการฉายได้สะดวก
สัญชาตญาณ #
การเข้าใจวิธีนี้ควรดูสมมติฐานของโมเดล ลักษณะข้อมูล และผลของการตั้งค่าพารามิเตอร์ต่อการทั่วไปของโมเดล
คำอธิบายโดยละเอียด #
สูตรสำคัญ #
ในกรณีสองคลาส เวกเตอร์ฉาย \(\mathbf{w}\) หาได้จากการเพิ่ม
$$ J(\mathbf{w}) = \frac{\mathbf{w}^\top \mathbf{S}_B \mathbf{w}}{\mathbf{w}^\top \mathbf{S}_W \mathbf{w}}, $$โดย \(\mathbf{S}_B\) คือเมทริกซ์ความแปรปรวนระหว่างคลาส และ \(\mathbf{S}_W\) คือภายในคลาส หากมีหลายคลาสจะได้มากสุด \(K-1\) เวกเตอร์ฉาย (เมื่อมี \(K\) คลาส) ซึ่งใช้ลดมิติได้
ทดลองด้วย Python #
โค้ดต่อไปนี้ฝึก LDA กับข้อมูลสองคลาสและวาดทั้งเส้นแบ่งและผลหลังฉาย
| |
เอกสารอ้างอิง #
- Fisher, R. A. (1936). The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7(2), 179 E88.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.