2.2.1
ลอจิสติกรีเกรสชัน
สรุป
- ลอจิสติกรีเกรสชันนำผลรวมเชิงเส้นของอินพุตผ่านฟังก์ชันซิกมอยด์เพื่อประมาณความน่าจะเป็นที่อยู่ในคลาส 1
- เอาต์พุตจำกัดอยู่ในช่วง \([0,1]\) จึงตั้ง threshold ได้ยืดหยุ่น และสัมประสิทธิ์ตีความเป็น log-odds ได้
- ฝึกด้วยการลดทอน cross-entropy (เท่ากับเพิ่มค่าความน่าจะเป็นร่วม) และสามารถเพิ่มโทษ L1/L2 เพื่อยับยั้งการเรียนรู้เกิน
LogisticRegressionใน scikit-learn ทำให้เทรนและวาดเส้นแบ่งได้ภายในไม่กี่บรรทัด
สัญชาตญาณ #
การเข้าใจวิธีนี้ควรดูสมมติฐานของโมเดล ลักษณะข้อมูล และผลของการตั้งค่าพารามิเตอร์ต่อการทั่วไปของโมเดล
คำอธิบายโดยละเอียด #
สูตรสำคัญ #
ความน่าจะเป็นของคลาส 1 เมื่ออินพุตเป็น \(\mathbf{x}\) คือ
$$ P(y=1 \mid \mathbf{x}) = \sigma(\mathbf{w}^\top \mathbf{x} + b) = \frac{1}{1 + \exp\left(-(\mathbf{w}^\top \mathbf{x} + b)\right)}. $$ค่าสัมประสิทธิ์หาได้จากการเพิ่มค่าลอการิทึมของความน่าจะเป็นร่วม
$$ \ell(\mathbf{w}, b) = \sum_{i=1}^{n} \Bigl[ y_i \log p_i + (1 - y_i) \log (1 - p_i) \Bigr], \quad p_i = \sigma(\mathbf{w}^\top \mathbf{x}_i + b), $$ซึ่งเท่ากับการลดทอน cross-entropy ส่วนโทษ L2 ทำให้สัมประสิทธิ์ไม่พุ่งสูง ส่วน L1 สามารถกดให้บางพจน์เป็นศูนย์
ทดลองด้วย Python #
ตัวอย่างต่อไปนี้ฝึกโมเดลบนข้อมูลสองมิติที่แบ่งเส้นตรงได้ แล้ววาดเส้นแบ่งพร้อมแผนที่ความน่าจะเป็น
| |
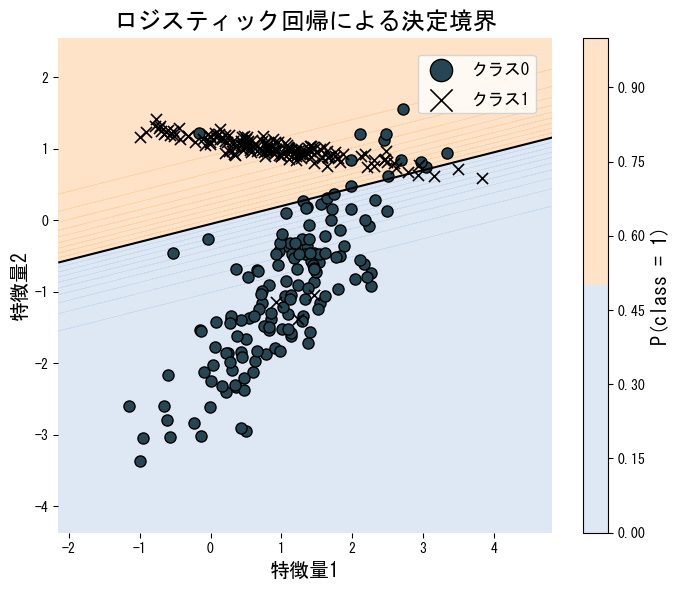
เอกสารอ้างอิง #
- Agresti, A. (2015). Foundations of Linear and Generalized Linear Models. Wiley.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.