2.2.3
เพอร์เซ็ปตรอน
สรุป
- เพอร์เซ็ปตรอนเป็นอัลกอริทึมออนไลน์เชิงคลาสสิกที่รับประกันการลู่เข้าภายในจำนวนรอบจำกัด หากข้อมูลจำแนกเชิงเส้นได้
- พยากรณ์ด้วยสัญลักษณ์ของ \(\mathbf{w}^\top \mathbf{x} + b\) และอัปเดตน้ำหนักเฉพาะเมื่อทำนายผิด
- กฎอัปเดตเรียบง่าย ทำให้จับแนวคิดการไล่ระดับและการขยับเส้นแบ่งทีละนิดผ่านอัตราเรียนรู้ได้ง่าย
- หากข้อมูลไม่เชิงเส้น ต้องขยายฟีเจอร์หรือใช้เคอร์เนลเพื่อขยายกำลังจำแนก
สัญชาตญาณ #
การเข้าใจวิธีนี้ควรดูสมมติฐานของโมเดล ลักษณะข้อมูล และผลของการตั้งค่าพารามิเตอร์ต่อการทั่วไปของโมเดล
คำอธิบายโดยละเอียด #
สูตรสำคัญ #
ฟังก์ชันพยากรณ์คือ
$$ \hat{y} = \operatorname{sign}(\mathbf{w}^\top \mathbf{x} + b) $$หากตัวอย่าง \((\mathbf{x}_i, y_i)\) ถูกจำแนกผิด ให้ปรับ
$$ \mathbf{w} \leftarrow \mathbf{w} + \eta\, y_i\, \mathbf{x}_i,\qquad b \leftarrow b + \eta\, y_i $$หากข้อมูลจำแนกเชิงเส้นได้ การทำซ้ำกฎนี้จะลู่เข้าภายในจำนวนก้าวจำกัด
ทดลองด้วย Python #
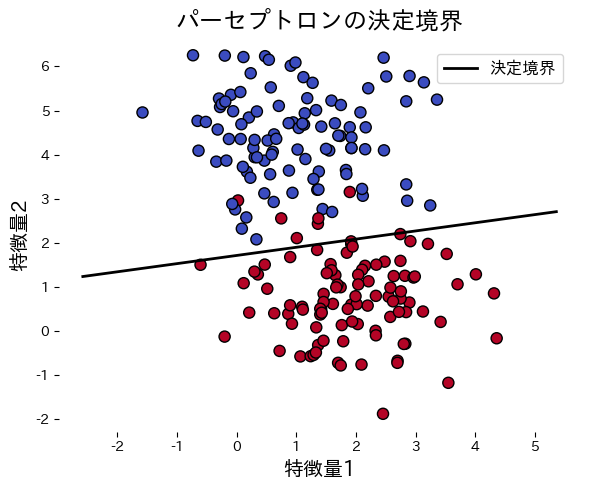
ตัวอย่างต่อไปนี้ฝึกเพอร์เซ็ปตรอนบนข้อมูลสังเคราะห์และวาดเส้นแบ่ง
| |
เอกสารอ้างอิง #
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, 65(6), 386 E08.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.