2.2.5
Support Vector Machine
สรุป
- SVM เรียนรู้เส้นแบ่งที่เพิ่มมาร์จินระหว่างคลาส จึงให้ความสำคัญกับการทั่วไปมากกว่าการฟิตข้อมูลฝึก
- Soft-margin SVM เพิ่มตัวแปร slack เพื่ออนุญาตให้บางจุดผิดพลาด และใช้พารามิเตอร์ \(C\) เพื่อควบคุมการลงโทษ
- Kernel trick แทนที่สเกลาร์โปรดักต์ด้วยเคอร์เนล ทำให้สร้างเส้นแบ่งไม่เชิงเส้นโดยไม่ต้องสร้างฟีเจอร์เพิ่ม
- การทำมาตรฐานและการค้นหาค่า \(C\), \(\gamma\) (หรือพารามิเตอร์เคอร์เนลอื่น) เป็นหัวใจของการได้ผลลัพธ์ที่ดี
สัญชาตญาณ #
การเข้าใจวิธีนี้ควรดูสมมติฐานของโมเดล ลักษณะข้อมูล และผลของการตั้งค่าพารามิเตอร์ต่อการทั่วไปของโมเดล
คำอธิบายโดยละเอียด #
สูตรสำคัญ #
กรณีแยกเชิงเส้นได้ ทำการเพิ่มประสิทธิภาพ
$$ \min_{\mathbf{w}, b} \ \frac{1}{2} \lVert \mathbf{w} \rVert_2^2 \quad \text{s.t.} \quad y_i(\mathbf{w}^\top \mathbf{x}_i + b) \ge 1. $$สำหรับข้อมูลจริงมักต้องใช้ soft margin โดยเพิ่มตัวแปร \(\xi_i\)
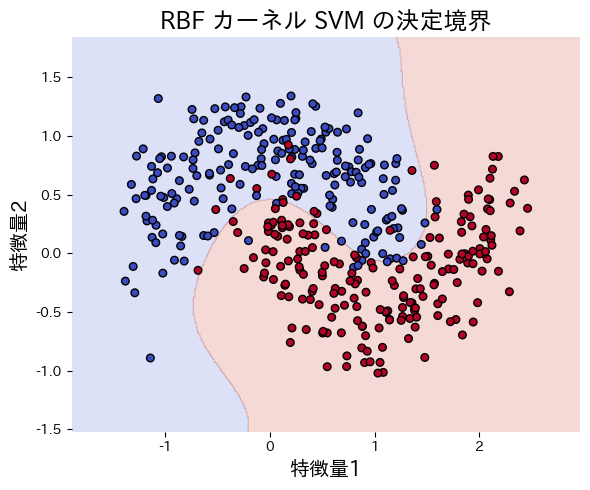
$$ \min_{\mathbf{w}, b, \boldsymbol{\xi}} \ \frac{1}{2} \lVert \mathbf{w} \rVert_2^2 + C \sum_{i=1}^{n} \xi_i \quad \text{s.t.} \quad y_i(\mathbf{w}^\top \mathbf{x}_i + b) \ge 1 - \xi_i. $$แทนที่ \(\mathbf{x}_i^\top \mathbf{x}_j\) ด้วยเคอร์เนล \(K(\mathbf{x}_i, \mathbf{x}_j)\) เพื่อสร้างเส้นแบ่งไม่เชิงเส้นได้ เช่น RBF, Polynomial, Sigmoid
ทดลองด้วย Python #
ตัวอย่างต่อไปนี้เปรียบเทียบเส้นแบ่งของ SVM แบบเชิงเส้นและ RBF บนข้อมูล make_moons
| |
เอกสารอ้างอิง #
- Vapnik, V. (1998). Statistical Learning Theory. Wiley.
- Smola, A. J., & Schölkopf, B. (2004). A Tutorial on Support Vector Regression. Statistics and Computing, 14(3), 199 E22.