2.5.4
DBSCAN
สรุป
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise) มองพื้นที่ที่แน่นเป็นคลัสเตอร์ ส่วนที่เบาบางเป็น noise
- ต้องกำหนดระยะ
epsและจำนวนเพื่อนบ้านขั้นต่ำmin_samplesเพื่อจัดประเภทจุดเป็น core / border / noise - ไม่ต้องกำหนดจำนวนคลัสเตอร์ล่วงหน้าและรองรับรูปทรงคลัสเตอร์ที่โค้งงอหรือซับซ้อนได้ดี
- ใช้กราฟ
min_samples-distance เพื่อเลือกepsและควรปรับสเกลฟีเจอร์ให้เทียบเคียงกันเพื่อผลลัพธ์ที่เสถียร
สัญชาตญาณ #
การเข้าใจวิธีนี้ควรดูสมมติฐานของโมเดล ลักษณะข้อมูล และผลของการตั้งค่าพารามิเตอร์ต่อการทั่วไปของโมเดล
คำอธิบายโดยละเอียด #
สูตรสำคัญ #
กำหนดชุดข้อมูล \(\mathcal{X}\) และระยะ \(\varepsilon\) ใกล้เคียงของจุด \(x_i\) คือ
$$ \mathcal{N}_\varepsilon(x_i) = \{\, x_j \in \mathcal{X} \mid \lVert x_i - x_j \rVert \le \varepsilon \,\}. $$หาก \(|\mathcal{N}_\varepsilon(x_i)| \ge \texttt{min_samples}\) จะเป็น core point เมื่อ core สองจุดเชื่อมถึงกัน (density reachable) จะถูกจัดอยู่คลัสเตอร์เดียว
ทดลองด้วย Python #
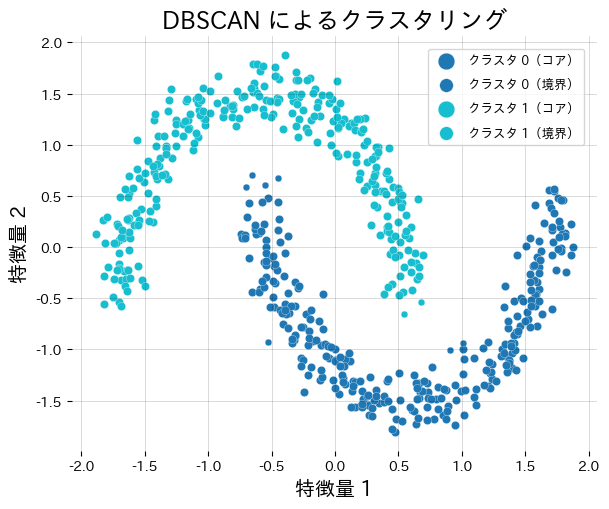
ตัวอย่างต่อไปนี้รัน DBSCAN บนข้อมูลรูปร่างพระจันทร์และรายงานจำนวนคลัสเตอร์/จำนวน noise
| |
เอกสารอ้างอิง #
- Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. (1996). A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. KDD.
- Schubert, E., Sander, J., Ester, M., Kriegel, H.-P., & Xu, X. (2017). DBSCAN Revisited, Revisited. ACM Transactions on Database Systems.
- scikit-learn developers. (2024). Clustering. https://scikit-learn.org/stable/modules/clustering.html